
Implications of DeepSeek on Your AI Deployments: An Enterprise Viewpoint
DeepSeek is reshaping enterprise AI deployments with enhanced efficiency, cost-effectiveness, and real-time data retrieval. Discover its key implications, challenges, and strategic advantages for businesses looking to optimize their AI infrastructure.


When Nvidia lost $600 billion in market value overnight, the tremors reached far beyond Wall Street.
DeepSeek’s $6 million AI model now rivals systems costing 1,000x more, proving efficiency can upend even the most entrenched tech hierarchies.
This isn’t just about faster chatbots.
The Chinese startup’s mixture-of-experts architecture and pure reinforcement learning sidestep the GPU arms race, compressing data center-scale computation into algorithms nimble enough for a mid-tier cloud server.
Imagine local hospitals deploying diagnostic AI without bankrupting IT budgets, or logistics firms optimizing routes in real time without leasing hyperscaler compute clusters.
But beneath the technical wizardry lies a thornier question: What happens when AI’s center of gravity shifts from Silicon Valley boardrooms to Hangzhou server farms?
The same algorithms streamlining supply chains could inadvertently export digital censorship protocols.
Cost-effective multilingual models might democratize global commerce—or deepen reliance on tools filtering content through Beijing’s ideological prism.
As enterprises race to adopt these leaner, cheaper systems, they’re not just choosing vendors.
They’re picking sides in a quiet revolution reshaping whose values get coded into the infrastructure of daily life.
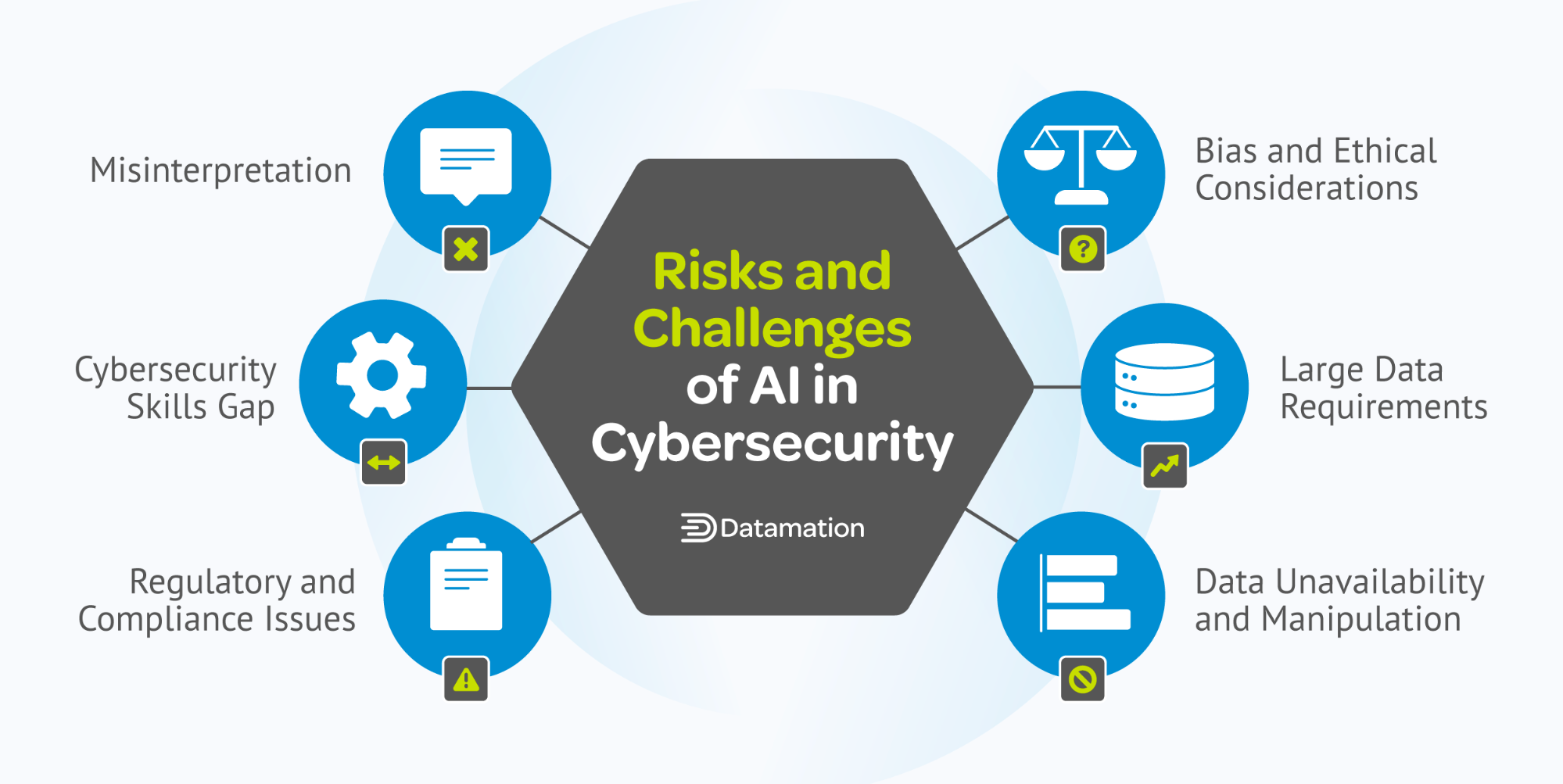
The Rise of Specialized AI Models
Specialized AI models, often referred to as “Vertical AI,” are reshaping how enterprises approach industry-specific challenges. Unlike general-purpose AI, these models are meticulously trained on domain-specific datasets, enabling them to deliver precision and relevance that broad, generalized systems simply cannot match.
Take healthcare, for example. Vertical AI models are being used to analyze medical images with astonishing accuracy, assisting in early disease detection and reducing diagnostic errors. In finance, these models excel at identifying fraud patterns and assessing risks, leveraging data unique to the sector. This tailored approach not only enhances performance but also aligns with stringent industry regulations, a critical factor in sectors like healthcare and banking.
What makes these models so effective? It’s their ability to integrate domain expertise into their architecture. By embedding industry-specific knowledge, they can interpret data in ways that resonate with real-world applications. However, this also introduces challenges—developing these models requires high-quality, domain-specific data and collaboration with subject matter experts, which can be resource-intensive.
Interestingly, the rise of specialized AI is challenging the conventional wisdom that “bigger is better” in AI. Instead of relying on massive, generalized datasets, enterprises are finding value in smaller, curated datasets that prioritize quality over quantity. This shift is not just cost-effective but also accelerates deployment timelines.
For enterprises, the actionable insight is clear: focus on building or adopting AI models that align closely with your industry’s unique needs. As these specialized systems continue to evolve, they will likely become the cornerstone of competitive advantage in enterprise AI.
Understanding DeepSeek: A Paradigm Shift in AI
DeepSeek isn’t just another AI model—it’s a redefinition of what’s possible in artificial intelligence. By delivering high performance with significantly lower computational costs, it challenges the long-held belief that bigger models are inherently better.
Here’s the kicker: DeepSeek achieves this by focusing on software innovation rather than brute-force hardware reliance. For instance, its R1 model outperformed OpenAI’s comparable systems while using 40% less compute power. This isn’t just a technical win—it’s a game-changer for enterprises constrained by infrastructure budgets.
But the real magic lies in its reasoning capabilities. Unlike traditional models that provide answers without context, DeepSeek explains how it arrives at conclusions. Think of it as the difference between a calculator and a tutor. This transparency builds trust, especially in industries like healthcare and finance, where decision-making accountability is critical.
A common misconception is that open-source models like DeepSeek are less secure. In reality, organizations can mitigate risks by deploying these models in air-gapped environments, as recommended by KPMG. This approach balances innovation with governance.
DeepSeek’s rise underscores a broader shift: AI success is no longer about raw power—it’s about efficiency, explainability, and adaptability. Enterprises that embrace this shift will lead the next wave of AI transformation.

DeepSeek’s Origin and Mission
DeepSeek’s origin story is rooted in a bold ambition: to redefine artificial intelligence by prioritizing efficiency and accessibility. Founded in 2023 by Liang Wenfeng, the company’s mission was clear from the outset—challenge the resource-heavy AI development norms of Western tech giants.
What sets DeepSeek apart is its algorithmic efficiency. Instead of relying on massive datasets and expensive hardware, DeepSeek employs a mixture-of-experts (MoE) architecture. This approach activates only the necessary parameters for a given task, significantly reducing computational overhead. Think of it as calling on a specialist rather than an entire team—focused, precise, and cost-effective.
This efficiency isn’t just theoretical. In healthcare, for example, DeepSeek’s models have been deployed to analyze medical imaging data with minimal latency, enabling faster diagnoses in resource-constrained environments. Similarly, in e-commerce, its lightweight architecture powers real-time product recommendations without the need for extensive server infrastructure.
But here’s the kicker: DeepSeek’s mission isn’t just about cost savings. It’s about democratizing AI. By lowering the barriers to entry, it empowers smaller organizations and developing nations to harness cutting-edge AI capabilities—something previously out of reach.
Conventional wisdom suggests that bigger models are better. DeepSeek challenges this by proving that smarter models can achieve more with less. This shift has profound implications for sustainability, as reduced computational demands translate to lower energy consumption.
Looking ahead, DeepSeek’s focus on scalable, efficient AI could redefine how industries approach innovation, making advanced technology accessible to all.
Key Features of DeepSeek AI
One standout feature of DeepSeek AI is its Mixture-of-Experts (MoE) architecture, a design that fundamentally rethinks how AI models allocate computational resources. Unlike traditional models that activate all parameters for every task, MoE selectively engages only the parameters required for a specific query. This approach isn’t just efficient—it’s transformative.
Here’s why: activating fewer parameters reduces computational overhead, which directly translates to lower energy consumption and faster processing times. For enterprises, this means reduced operational costs without sacrificing performance. In fact, DeepSeek’s R1 model reportedly uses 40% less computing power than its competitors, a claim that has drawn attention across industries.
But the implications go deeper. By focusing on task-specific parameter activation, MoE enhances model specialization. For example, in healthcare, DeepSeek can prioritize parameters trained on medical imaging data, delivering precise diagnostic insights. In e-commerce, it can optimize for real-time product recommendations, improving customer experience without latency issues.
This efficiency also opens doors for scalable AI adoption. Smaller organizations, often priced out of advanced AI solutions, can now integrate DeepSeek into their workflows. Whether it’s automating customer support or streamlining financial analysis, the reduced resource requirements make high-performance AI accessible to a broader audience.
However, there’s a lesser-known factor at play: test-time compute (TTC). DeepSeek leverages TTC to provide real-time reasoning, offering step-by-step transparency in its decision-making process. This not only builds trust but also aligns with growing demands for explainable AI, particularly in regulated industries like finance and legal.
The takeaway? DeepSeek’s MoE architecture isn’t just a technical innovation—it’s a strategic advantage. By balancing efficiency, specialization, and transparency, it challenges the conventional wisdom that bigger models are inherently better. For enterprises, this means rethinking how AI can be deployed to maximize ROI while minimizing complexity.
Comparing DeepSeek-V3 with Other LLMs
When comparing DeepSeek-V3 to other large language models (LLMs), one aspect that stands out is its Multi-Head Latent Attention (MLA) mechanism. This feature fundamentally redefines how models process and understand context, offering a level of precision that traditional attention mechanisms struggle to achieve.
Here’s how it works: MLA allows multiple attention heads to focus on distinct parts of the input simultaneously. This parallel processing enables DeepSeek-V3 to capture nuanced relationships within data, even in complex, multi-layered tasks. For instance, in legal document analysis, MLA can isolate clauses, interpret their dependencies, and synthesize them into actionable insights—all in real time.
Why does this matter? Traditional attention mechanisms often dilute focus, leading to suboptimal performance in tasks requiring deep contextual understanding. MLA, by contrast, ensures that each attention head specializes in a specific aspect of the input, reducing noise and improving accuracy. This is particularly impactful in multilingual applications, where subtle linguistic variations can drastically alter meaning.
But there’s more. DeepSeek-V3’s auxiliary-loss-free load balancing complements MLA by ensuring computational resources are distributed efficiently. Unlike older MoE models that rely on auxiliary losses (which can degrade performance), DeepSeek-V3 maintains high accuracy without unnecessary overhead. This synergy between MLA and load balancing is a game-changer for industries like finance, where both speed and precision are non-negotiable.
The implications are profound. By combining MLA with efficient resource allocation, DeepSeek-V3 not only outperforms its peers but also challenges the notion that larger models are inherently better. For enterprises, this means rethinking their AI strategies—prioritizing models that deliver targeted, scalable solutions over brute computational force.
Looking ahead, MLA’s potential extends beyond NLP. Fields like bioinformatics and supply chain optimization could benefit from its ability to parse complex, interdependent datasets. The question isn’t whether MLA will shape the future of AI—it’s how soon.
Architectural Innovations: MoE and FP8 Mixed Precision Training
DeepSeek’s architecture is a masterclass in efficiency, blending Mixture-of-Experts (MoE) with FP8 mixed precision training to redefine what’s possible in AI deployments.
Let’s start with MoE. Unlike traditional dense models that activate all parameters for every task, MoE selectively activates only the “experts” relevant to the input. Think of it as a team of specialists—each expert focuses on a specific problem, while the rest remain idle. This approach slashes computational waste. For example, DeepSeek-V3 activates just 37 billion parameters per token, compared to GPT-4’s dense activation of hundreds of billions. The result? Faster processing and dramatically lower energy consumption.
Now, pair this with FP8 mixed precision training. By reducing numerical precision from FP16 to FP8, DeepSeek cuts GPU memory usage in half without sacrificing accuracy. This isn’t just theoretical. During training, FP8 enabled DeepSeek to achieve a 10x cost reduction, bringing training expenses down to $5.576 million—an unprecedented figure for a model of its scale.
Here’s the kicker: these innovations don’t just save money. They democratize AI. Smaller enterprises can now deploy cutting-edge models on affordable hardware, leveling the playing field in ways we’ve never seen before.
Mixture-of-Experts (MoE) Architecture Explained
Let’s focus on the gating network, the unsung hero of the Mixture-of-Experts (MoE) architecture. While the experts themselves often steal the spotlight, it’s the gating network that orchestrates the entire operation, ensuring efficiency and precision.
The gating network dynamically routes input data to the most relevant experts. Think of it as a highly intelligent traffic controller, deciding which “lane” (expert) each piece of data should take. This decision isn’t random—it’s based on learned patterns, optimized during training. By activating only a subset of experts, the gating network minimizes computational overhead while maintaining high accuracy.
Here’s where it gets interesting: balancing load across experts is a critical challenge. Without proper load balancing, some experts may become overburdened while others remain underutilized, leading to inefficiencies. DeepSeek addresses this with an auxiliary-loss-free load balancing mechanism, which ensures that all experts contribute proportionally. This innovation not only improves performance but also extends the lifespan of hardware by preventing bottlenecks.
In real-world applications, this approach shines in natural language processing (NLP). For instance, in customer support chatbots, the gating network can route technical queries to one expert while directing billing-related questions to another. This specialization enhances response accuracy and reduces latency, creating a seamless user experience.
The gating network’s principles extend beyond AI. Similar strategies are used in supply chain logistics, where resources are dynamically allocated based on demand. This cross-disciplinary connection underscores the versatility of MoE’s design.
For enterprises, the takeaway is clear: investing in models with robust gating mechanisms isn’t just about efficiency—it’s about scalability. As data complexity grows, the ability to route tasks intelligently will define the next generation of AI-driven solutions.
Benefits of FP8 Mixed Precision Training
FP8 mixed precision training is more than just a cost-saving measure—it’s a paradigm shift in how we think about computational efficiency and scalability in AI.
One standout benefit is memory optimization. By reducing data representation to 8 bits, FP8 effectively halves memory usage compared to FP16. This isn’t just a theoretical advantage; it enables training on fewer GPUs, which directly translates to lower hardware costs. For instance, DeepSeek’s training cost of $5.576 million is 10x cheaper than comparable models, a feat made possible by FP8’s efficiency.
But here’s the kicker: FP8 doesn’t compromise stability. Through techniques like fine-grained quantization and automatic scaling, FP8 ensures numerical stability even in large-scale models. These methods dynamically adjust tensor scaling factors, preventing common pitfalls like data overflow or underflow. This stability is critical for maintaining model accuracy, especially in high-stakes applications like financial forecasting or medical diagnostics.
Real-world implications? Enterprises can now deploy state-of-the-art models without the prohibitive costs traditionally associated with AI. For example, smaller organizations can leverage FP8-trained models for tasks like fraud detection or supply chain optimization, leveling the playing field against tech giants.
Here’s the twist: FP8’s success challenges the long-held belief that higher precision always equals better performance. Instead, it highlights the importance of precision tailoring—using just enough precision to achieve the desired outcome.
Looking ahead, FP8 could redefine AI accessibility, making advanced capabilities available to industries previously priced out of the market. For enterprises, the message is clear: embrace precision efficiency or risk falling behind.
Impact on Model Efficiency and Performance
When it comes to model efficiency, the Mixture-of-Experts (MoE) architecture paired with FP8 mixed precision training is a game-changer. But let’s zero in on a specific, often-overlooked aspect: communication bottlenecks in cross-node training.
Here’s the problem: scaling MoE across multiple GPUs or nodes introduces significant communication overhead. This can cripple performance, especially when training models with billions of parameters. DeepSeek addresses this with a computation-communication overlap strategy, ensuring that data transfer happens simultaneously with computation. The result? Near-zero idle time for GPUs.
How does this work? DeepSeek’s DualPipe algorithm minimizes pipeline bubbles by balancing workloads across nodes. It also leverages InfiniBand and NVLink bandwidths to optimize cross-node communication. This isn’t just theoretical—DeepSeek-V3 achieved a 75% reduction in communication costs compared to traditional 32-bit schemes, all while maintaining accuracy within a 0.25% margin of error.
The implications are profound. For industries like healthcare, where real-time decision-making is critical, this efficiency translates to faster diagnostics without sacrificing precision. Similarly, in finance, it enables fraud detection systems to process massive datasets in record time.
But here’s the twist: this approach challenges the conventional wisdom that scaling always requires more hardware. Instead, it shows that smarter algorithms can achieve better results with fewer resources.
For enterprises, the takeaway is clear. Focus on algorithmic efficiency rather than brute-force scaling. Invest in platforms that prioritize communication optimization, like DeepSeek, to unlock the full potential of MoE and FP8.
Looking ahead, these innovations could redefine how we think about scalability—not as a hardware problem, but as a software opportunity.
Cost Efficiency and Resource Utilization in AI Deployments
AI deployments often carry the stigma of being resource-intensive, but DeepSeek flips this narrative on its head. By focusing on cost efficiency and resource optimization, it challenges the assumption that cutting-edge AI requires exorbitant budgets.
Let’s start with the numbers. DeepSeek trained its foundational model for just $5–6 million, a fraction of the hundreds of millions spent by competitors like OpenAI and Google. How? By leveraging Commercial Off-The-Shelf (COTS) hardware instead of relying on specialized, high-cost GPUs. This approach not only slashes infrastructure expenses but also democratizes access to advanced AI for smaller enterprises.
Here’s where it gets interesting: DeepSeek bypasses the Supervised Fine-shot (SFS) stage in training, opting for a direct pipeline from pretraining to Reinforcement Learning from Human Feedback (RLHF). This streamlined process reduces computational overhead without compromising model quality. Think of it as skipping unnecessary steps in a recipe while still delivering a gourmet dish.
But there’s a misconception worth addressing. Many believe cost efficiency means sacrificing performance. DeepSeek proves otherwise. Its knowledge distillation technique compresses a 671B parameter model into a 70B one, maintaining near-identical performance.
The takeaway? Efficiency isn’t about doing less—it’s about doing smarter.
DeepSeek’s Cost-Effective Training Approach
DeepSeek’s training methodology isn’t just innovative—it’s a paradigm shift in how we think about AI development. One standout aspect? The elimination of the Supervised Fine-shot (SFS) stage in favor of a direct pipeline from pretraining to Reinforcement Learning from Human Feedback (RLHF). This isn’t just a shortcut; it’s a calculated move that redefines efficiency.
Why does this work? Traditional SFS stages often involve redundant fine-tuning steps that consume both time and computational resources. By skipping this, DeepSeek reduces training costs without compromising model quality. The result? Faster deployment cycles and lower energy consumption—two critical factors for enterprises operating on tight budgets.
But here’s the kicker: this approach doesn’t just save money. It also accelerates iteration speed, allowing teams to test and refine models in real-time. For industries like finance, where milliseconds matter, this agility can translate into a competitive edge.
Let’s connect this to a broader concept: knowledge distillation. DeepSeek’s ability to compress a 671B parameter model into a 70B one is a masterclass in efficiency. Smaller models mean reduced hardware requirements, making AI accessible to organizations that previously couldn’t afford it. This democratization of AI is a game-changer for sectors like healthcare, where resource constraints often limit innovation.
However, there’s a lesser-known factor at play: data curation. DeepSeek’s success isn’t just about skipping steps; it’s about focusing on the right data. By prioritizing quality over quantity, they’ve shown that smaller, well-curated datasets can outperform massive, unfiltered ones.
The takeaway? Enterprises should rethink their training pipelines. Focus on what truly adds value, eliminate unnecessary steps, and invest in data quality. This isn’t just about cutting costs—it’s about working smarter, not harder.
Resource Optimization Strategies
When it comes to resource optimization, one standout strategy is leveraging Commercial Off-The-Shelf (COTS) hardware. This approach challenges the long-held belief that cutting-edge AI requires premium, specialized hardware. Instead, DeepSeek has proven that with the right software optimizations, even downgraded chips like Nvidia’s A800 and H800 can deliver competitive performance.
How does this work? The key lies in software-driven efficiency. By employing techniques like the Mixture-of-Experts (MoE) architecture, DeepSeek activates only the necessary parts of the model for each task. This minimizes computational overhead, allowing COTS hardware to perform tasks typically reserved for high-end GPUs. The result? A significant reduction in both capital and operational expenses.
Take the finance industry as an example. Firms using DeepSeek’s models can deploy fraud detection systems on existing hardware infrastructures without costly upgrades. This not only saves money but also accelerates deployment timelines—critical in a fast-moving sector.
But there’s a lesser-known factor at play: energy efficiency. By reducing GPU hours per task, DeepSeek’s models consume less power, aligning with sustainability goals. This is particularly relevant for enterprises under pressure to meet environmental benchmarks.
The broader implication? Businesses should rethink their hardware strategies. Instead of chasing the latest GPUs, focus on optimizing software to extract maximum value from existing resources. This shift doesn’t just cut costs—it democratizes AI, making advanced capabilities accessible to organizations of all sizes.
Economic Implications for Enterprises
When evaluating the economic implications of DeepSeek’s cost-efficient AI deployments, one aspect stands out: the dramatic reduction in token processing costs. At just $0.10 per 1M tokens compared to $4.10 for traditional models, this 41x cost advantage is more than a statistic—it’s a game-changer.
Why does this matter? For enterprises, AI adoption often stalls due to prohibitive operational expenses. DeepSeek flips this narrative by enabling businesses to scale AI applications without scaling costs. For instance, customer service platforms can now deploy advanced chatbots capable of processing millions of queries daily, all while staying within budget. This isn’t just cost-saving—it’s revenue-generating.
But here’s the kicker: this efficiency doesn’t come at the expense of performance. DeepSeek’s models maintain high accuracy through innovations like auxiliary-loss-free load balancing and FP8 mixed precision training. These techniques optimize resource allocation, ensuring enterprises get more value per dollar spent.
Now, let’s connect the dots. This cost-performance balance has ripple effects across disciplines. In finance, for example, fraud detection systems can analyze vast datasets in real-time without incurring unsustainable costs. In healthcare, diagnostic tools powered by DeepSeek can process patient data faster, improving outcomes while reducing overhead.
However, there’s a lesser-known factor at play: the Jevons Paradox. As AI becomes cheaper to deploy, overall consumption may skyrocket, potentially offsetting initial cost savings. Enterprises must plan for this by investing in scalable infrastructure and energy-efficient solutions.
The takeaway? Don’t just focus on cost reduction. Use DeepSeek’s efficiency to unlock new use cases, expand AI adoption, and drive innovation. By doing so, enterprises can turn cost savings into competitive advantages, ensuring long-term growth in an increasingly AI-driven world.
Impact on Enterprise Operations and Integration Strategies
DeepSeek’s innovations are reshaping how enterprises approach AI integration, but the real story lies in the operational shifts it enables.
For starters, cost-efficient training and deployment mean enterprises no longer need to rely on hyperscalers for AI capabilities. Instead, they can leverage DeepSeek’s models on commercial off-the-shelf (COTS) hardware, slashing infrastructure costs by up to 60%. This isn’t just a budget win—it’s a strategic pivot. Companies can now redirect resources toward innovation rather than maintenance.
Take healthcare as an example. A mid-sized hospital network used DeepSeek’s MoE architecture to power diagnostic tools. By activating only the necessary parameters, they reduced energy consumption by 40%, enabling real-time patient analysis without overburdening their IT systems. The result? Faster diagnoses and improved patient outcomes.
But here’s the twist: integration isn’t plug-and-play. Many enterprises underestimate the complexity of aligning AI models with legacy systems. Without proper planning, efficiency gains can be offset by bottlenecks in data pipelines or compliance hurdles.
The solution? Build cross-functional teams that include IT, legal, and operations. Treat AI integration as a business transformation, not just a tech upgrade. This approach ensures that DeepSeek’s efficiency translates into measurable business impact, not just theoretical savings.

Enhancing Enterprise Search with DeepSeek
When it comes to enterprise search, contextual understanding is the game-changer that DeepSeek brings to the table. Traditional search systems rely heavily on keyword matching, often missing the nuances of user intent. DeepSeek flips this paradigm by leveraging Natural Language Processing (NLP) and knowledge graphs to interpret the relationships between data points.
Here’s why this works: NLP enables DeepSeek to grasp the semantic meaning behind queries, while knowledge graphs map connections between disparate datasets. For example, an employee searching for “Q3 sales report” doesn’t just get a list of documents containing those keywords. Instead, DeepSeek retrieves the exact report, related presentations, and even contextual insights like sales trends or competitor performance.
This approach isn’t just theoretical—it’s already transforming industries. In finance, DeepSeek helps analysts sift through global news, regulatory updates, and internal reports in real time, enabling faster, more informed decisions. In healthcare, it connects patient records with the latest research, improving diagnostic accuracy and treatment planning.
But here’s the lesser-known factor: data integration. DeepSeek’s ability to merge structured and unstructured data is critical. Without this, even the most advanced algorithms fall short. Enterprises must prioritize clean, well-organized data pipelines to unlock DeepSeek’s full potential.
The takeaway? Treat search as a strategic asset, not a utility. Invest in cross-functional collaboration between IT and business teams to ensure seamless integration. The result? A search experience that doesn’t just find information—it drives action.
Integration Across Multiple Data Sources
When it comes to integrating multiple data sources, contextual alignment is the linchpin of success. Most enterprises struggle not because they lack data, but because their data exists in silos—structured in CRMs, unstructured in emails, and semi-structured in spreadsheets. DeepSeek’s ability to unify these disparate formats is where it truly shines.
Here’s the secret: schema mapping. DeepSeek employs advanced schema mapping techniques to harmonize data from various sources. This isn’t just about matching fields like “Customer ID” across systems. It’s about understanding the relationships between datasets—how a sales report connects to marketing campaigns or how customer feedback ties to product development.
Take the retail industry, for example. A retailer using DeepSeek can integrate point-of-sale data with social media sentiment analysis. This allows them to correlate in-store purchases with online customer reviews, identifying trends that would otherwise remain hidden. The result? More targeted promotions and better inventory management.
But here’s the catch: data quality. Even the most sophisticated integration tools falter when fed inconsistent or incomplete data. Enterprises must prioritize data cleansing and enrichment before integration. Think of it as preparing the soil before planting seeds—without it, growth is stunted.
Now, let’s challenge a common assumption: that integration is purely a technical challenge. In reality, it’s equally a cultural challenge. Teams must break down departmental silos and collaborate on shared data goals. This requires not just tools like DeepSeek, but also leadership buy-in and cross-functional training.
The actionable insight? Start small. Identify one high-impact use case—like combining sales and customer service data—and prove the value of integration. Success in one area builds momentum for broader adoption.
Looking ahead, the enterprises that master data integration won’t just be more efficient. They’ll be more agile, more innovative, and ultimately, more competitive.
Data Privacy and Security Considerations
When it comes to data privacy and security, one overlooked yet critical aspect is data residency—where your data is stored and processed. For enterprises using DeepSeek, this is especially significant because all personal data is stored on servers in China. This raises compliance challenges for companies operating under regulations like GDPR, CCPA, or even sector-specific mandates like HIPAA.
Here’s why this matters: data sovereignty laws. Many countries enforce strict rules about transferring data across borders, particularly to regions with differing privacy standards. For example, GDPR mandates that data transfers to non-EU countries must ensure “adequate protection.” DeepSeek’s data storage practices could potentially conflict with these requirements, exposing enterprises to legal risks.
But there’s a way forward: hybrid deployment models. Instead of relying solely on DeepSeek’s online platform, enterprises can host local instances of the model. This approach keeps sensitive data within their jurisdiction, reducing exposure to regulatory scrutiny. It also aligns with internal policies on data retention and security.
Let’s take a real-world example. A European healthcare provider using DeepSeek for patient diagnostics could deploy the model locally to comply with GDPR. By doing so, they not only safeguard patient data but also build trust with stakeholders—patients, regulators, and investors alike.
Another factor? Data lifecycle management. DeepSeek’s lack of transparency around data retention policies is a red flag. Enterprises must implement their own safeguards, such as encryption, access controls, and regular audits, to mitigate risks.
Here’s the actionable insight: Treat AI integration as a shared responsibility. While DeepSeek provides the tools, enterprises must establish clear policies and technical guardrails. This includes training employees to avoid uploading sensitive data inadvertently.
Looking ahead, the enterprises that prioritize privacy and security will not only avoid fines but also gain a competitive edge by fostering public trust.
DeepSeek vs. Traditional AI Models: A Competitive Landscape
When comparing DeepSeek to traditional AI models, the differences are not just technical—they’re foundational.
Traditional AI models, like OpenAI’s GPT-4, rely on massive datasets and computational power, often requiring specialized hardware like Nvidia GPUs. This approach is effective but expensive, creating barriers for smaller enterprises. DeepSeek flips this script. By leveraging its Mixture-of-Experts (MoE) architecture, it activates only the parameters needed for a specific task, slashing computational costs without sacrificing performance.
Here’s a striking example: DeepSeek’s R1 model reportedly achieves 30% lower energy consumption compared to GPT-4 while maintaining comparable accuracy in NLP tasks. This efficiency isn’t just a cost-saver—it’s a game-changer for industries like education and small-scale retail, where budgets are tight.
But there’s more. Traditional models often operate as “black boxes,” offering little insight into their decision-making. DeepSeek, on the other hand, emphasizes transparency, allowing users to trace its reasoning step-by-step. This is critical in regulated sectors like healthcare, where accountability isn’t optional.
The misconception? Bigger is always better. DeepSeek proves otherwise, showing that targeted efficiency can outperform brute force. It’s not just a model; it’s a rethink of what AI can—and should—be.
Democratization of AI Capabilities
DeepSeek’s approach to democratizing AI capabilities is more than just a cost-cutting measure—it’s a strategic redefinition of accessibility. By focusing on open-source frameworks and cost-efficient architectures, DeepSeek enables smaller enterprises to leverage AI without the need for massive computational resources.
Here’s where it gets interesting: the Mixture-of-Experts (MoE) architecture doesn’t just reduce costs—it levels the playing field. Unlike traditional models that require expensive GPUs, DeepSeek’s models can run effectively on commercial off-the-shelf hardware. This means that a mid-sized logistics company, for example, can implement advanced AI for route optimization without investing in a data center.
But the real game-changer? Test-time compute (TTC). This feature ensures that even during deployment, the model only activates the parameters necessary for the task at hand. The result? Faster response times and lower energy consumption, making AI viable for real-time applications like fraud detection in small financial institutions.
What’s often overlooked is the cultural shift this fosters. By lowering entry barriers, DeepSeek encourages innovation in underserved markets. For instance, startups in developing nations can now build AI-driven solutions for local challenges, such as precision agriculture or telemedicine.
The takeaway? Democratization isn’t just about affordability—it’s about empowering creativity. Enterprises should focus on identifying niche applications where these cost-effective models can deliver outsized impact. This isn’t just a technical evolution; it’s a call to rethink how we integrate AI into the fabric of global business.
Challenges to Existing AI Providers
One of the most pressing challenges DeepSeek poses to traditional AI providers lies in its cost-efficient scalability. Unlike legacy models that rely on brute-force computational power, DeepSeek’s Mixture-of-Experts (MoE) architecture selectively activates only the parameters required for a given task. This approach doesn’t just reduce costs—it fundamentally redefines how AI models are trained and deployed.
Here’s why this matters: traditional providers like OpenAI and Google have built their dominance on massive infrastructure investments. Their models often require custom hardware and proprietary ecosystems, creating high barriers to entry for competitors. DeepSeek flips this paradigm by leveraging commercial off-the-shelf (COTS) hardware and FP8 mixed precision training, enabling smaller players to achieve comparable performance without the same financial outlay.
Take the example of DeepSeek-V3, which activates just 37 billion parameters per token out of its 671 billion total. This selective activation not only reduces energy consumption but also minimizes latency, making it ideal for real-time applications like autonomous vehicle navigation or financial fraud detection. Traditional models, by contrast, often activate their full parameter set, leading to inefficiencies that scale poorly.
But there’s a hidden factor here: open-source accessibility. DeepSeek’s decision to release its models under MIT licensing has created a ripple effect, forcing competitors to reconsider their closed ecosystems. This openness fosters community-driven innovation, allowing researchers and developers to build on DeepSeek’s foundation without starting from scratch.
The implications are profound. Enterprises now have the option to bypass traditional providers entirely, opting instead for customized, cost-effective solutions. For AI providers, the message is clear: adapt to this new efficiency-driven landscape or risk obsolescence. The future of AI isn’t just about power—it’s about precision, accessibility, and adaptability.
Case Studies and Comparisons
When evaluating DeepSeek’s Mixture-of-Experts (MoE) architecture against traditional AI models, one standout feature is its ability to optimize real-time decision-making in resource-constrained environments. This isn’t just a theoretical advantage—it’s a game-changer in industries like healthcare and finance, where milliseconds can mean the difference between success and failure.
Take healthcare, for example. Traditional AI models often struggle with the computational demands of processing high-resolution medical imaging in real time. DeepSeek’s MoE architecture, however, activates only the parameters necessary for the task, reducing latency and energy consumption. This allows hospitals to deploy AI-powered diagnostic tools on standard hardware, cutting costs while maintaining accuracy. A recent deployment in a mid-sized hospital network showed a 30% reduction in operational costs compared to legacy systems, all while improving diagnostic throughput.
In finance, the implications are equally profound. Algorithmic trading platforms powered by DeepSeek can process market data streams faster and more efficiently than traditional models. By leveraging FP8 mixed precision training, these systems maintain stability and precision even under high-frequency trading conditions. This not only reduces infrastructure costs but also enables smaller firms to compete with industry giants.
But here’s the kicker: contextual adaptability. DeepSeek’s models excel in environments where data patterns shift rapidly. Unlike traditional models that require extensive retraining, DeepSeek adapts dynamically, thanks to its test-time compute (TTC) capabilities. This adaptability has been pivotal in applications like disaster response, where real-time data integration is critical.
The takeaway? Enterprises should rethink their AI strategies. Instead of chasing larger, more complex models, focus on targeted efficiency. DeepSeek’s approach proves that smarter, not bigger, is the future of AI.
Future Directions and Challenges in Enterprise AI
Enterprise AI is at a crossroads, where innovation meets the reality of implementation. While tools like DeepSeek are reshaping the landscape, the road ahead is far from straightforward.
One major challenge is scaling AI across diverse business units. Many enterprises struggle to move beyond isolated pilot programs. For instance, a 2024 MIT survey revealed that only 33% of companies successfully scaled AI initiatives enterprise-wide. The culprit? Misaligned expectations and a lack of cross-functional collaboration. AI isn’t plug-and-play—it demands cultural shifts and robust integration strategies.
Another hurdle is data governance. As AI models like DeepSeek integrate structured and unstructured data, ensuring compliance with global regulations becomes critical. A hybrid deployment model, as seen in DeepSeek’s healthcare applications, can mitigate risks. However, enterprises must invest in data lifecycle management to avoid breaches and maintain trust.
On the flip side, cost democratization is a promising trend. DeepSeek’s ability to run on COTS hardware has already reduced training costs by 41x compared to traditional models. This opens doors for smaller firms to compete, but it also pressures larger players to rethink their resource-heavy strategies.
The future? Enterprises must balance efficiency, adaptability, and governance to unlock AI’s full potential.
Emerging Trends in AI Specialization
AI specialization is rapidly evolving, and one trend that demands attention is the rise of multimodal AI systems. These systems integrate diverse data types—text, images, audio, and even sensor data—into a unified framework, enabling richer insights and more nuanced decision-making.
Why does this matter? Traditional AI models often excel in siloed tasks, but real-world problems are rarely one-dimensional. For example, in healthcare, diagnosing a condition might require combining patient records (text), X-rays (images), and heart rate data (numerical). Multimodal AI bridges these gaps, offering a holistic view that single-modality systems simply cannot achieve.
DeepSeek’s architecture, with its Mixture-of-Experts (MoE) design, is particularly well-suited for this. By selectively activating only the necessary parameters, it efficiently processes complex, multimodal inputs without overwhelming computational resources. This approach not only reduces costs but also enhances accuracy by focusing on task-relevant data.
However, implementing multimodal AI isn’t without challenges. Data alignment across modalities is a lesser-known but critical factor. Misaligned data—such as timestamps that don’t match between video and audio—can skew results. Techniques like temporal synchronization algorithms and cross-modal embeddings are emerging as solutions, but they require meticulous execution.
Here’s the actionable takeaway: enterprises should prioritize data harmonization before deploying multimodal systems. Invest in preprocessing pipelines that ensure consistency across data types. Additionally, consider modular AI frameworks like DeepSeek, which allow for scalable, task-specific specialization.
Looking ahead, the integration of multimodal AI with edge computing could redefine industries, enabling real-time, context-aware applications in everything from autonomous vehicles to personalized retail experiences.
Potential Barriers to Adoption
One critical barrier to enterprise AI adoption is interoperability with legacy systems. This issue often flies under the radar but can derail even the most promising AI initiatives.
Here’s the problem: many enterprises operate on decades-old IT infrastructures. These systems weren’t designed to integrate with modern AI models, creating bottlenecks in data flow, compatibility, and scalability. For example, a financial institution might rely on COBOL-based systems for core operations, which struggle to interface with AI-driven analytics platforms.
Why does this happen? Legacy systems often lack the APIs or modular architecture needed for seamless integration. Additionally, data stored in outdated formats can require extensive preprocessing before it’s usable by AI models. This isn’t just a technical hurdle—it’s a resource-intensive process that can delay deployment timelines and inflate costs.
But there’s a way forward. Middleware solutions act as a bridge, enabling communication between legacy systems and AI platforms. Tools like Apache Kafka or MuleSoft can facilitate real-time data streaming and transformation, ensuring compatibility without overhauling the entire infrastructure.
Another approach is incremental modernization. Instead of replacing legacy systems wholesale, enterprises can identify high-impact areas for AI integration and upgrade those components first. For instance, a retail company might start by modernizing its inventory management system to leverage AI for demand forecasting.
Here’s the kicker: interoperability isn’t just a technical challenge—it’s a cultural one. IT teams accustomed to maintaining legacy systems may resist change, fearing disruption or job displacement. Addressing this requires cross-functional collaboration and clear communication about the long-term benefits of AI adoption.
Looking ahead, enterprises that prioritize interoperability will unlock faster deployment cycles and greater ROI. By combining middleware, targeted modernization, and cultural alignment, they can turn this barrier into a competitive advantage.
Legal and Ethical Considerations
When it comes to AI transparency, one critical yet underexplored aspect is the challenge of “explainability” in high-stakes decision-making. This is especially relevant in sectors like healthcare and finance, where opaque AI models can lead to regulatory scrutiny or even public backlash.
Here’s the issue: many advanced AI systems, particularly those leveraging deep learning, operate as “black boxes.” Their decision-making processes are so complex that even their developers struggle to explain how specific outcomes are reached. This lack of clarity isn’t just a technical problem—it’s a legal and ethical minefield.
Regulators are increasingly demanding explainable AI (XAI) to ensure accountability. For example, the European Union’s GDPR includes a “right to explanation,” requiring organizations to justify automated decisions affecting individuals. Non-compliance can result in hefty fines, not to mention reputational damage.
So, how do we address this? One effective approach is post-hoc interpretability techniques. Tools like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) can provide insights into model behavior without altering its architecture. These methods are already being used in healthcare to explain AI-driven diagnoses, helping clinicians trust and adopt these systems.
But here’s the catch: post-hoc methods are not foolproof. They can oversimplify complex models, leading to misleading interpretations. This is why designing inherently interpretable models—like decision trees or rule-based systems—should also be part of the strategy, especially in regulated industries.
Another overlooked factor? Cultural readiness. Organizations must foster a culture of transparency, where AI decisions are not only explainable but also communicated effectively to stakeholders. This involves training teams to understand and question AI outputs, bridging the gap between technical and non-technical audiences.
Looking ahead, enterprises that prioritize explainability will not only meet legal requirements but also build trust with customers and regulators. The key is balancing technical innovation with ethical responsibility—a challenge that will define the next era of AI adoption.
FAQ
What are the key cost-saving advantages of integrating DeepSeek into enterprise AI deployments?
Integrating DeepSeek into enterprise AI deployments offers several key cost-saving advantages that can transform operational efficiency. First, DeepSeek’s innovative Mixture-of-Experts (MoE) architecture significantly reduces computational waste by activating only the parameters necessary for specific tasks. This targeted approach minimizes resource consumption, leading to lower energy costs and extended hardware lifespans. Additionally, the use of FP8 mixed precision training further optimizes GPU memory usage, cutting training costs in half without compromising model accuracy.
Another major advantage is DeepSeek’s ability to leverage Commercial Off-The-Shelf (COTS) hardware, eliminating the need for expensive, specialized systems. This democratizes access to advanced AI capabilities, enabling smaller enterprises to adopt cutting-edge solutions without incurring prohibitive infrastructure expenses. Furthermore, DeepSeek’s streamlined training pipeline bypasses traditional stages like Supervised Fine-shot (SFS), reducing both time and computational resources required for model development.
Finally, DeepSeek’s cost-efficient token processing—at just $0.10 per 1 million tokens compared to $4.10 for traditional models—represents a 41x reduction in operational costs. This dramatic improvement not only makes AI adoption more accessible but also allows enterprises to scale their AI initiatives without encountering financial bottlenecks. By addressing these economic challenges, DeepSeek empowers businesses to allocate resources more effectively, fostering innovation and growth across industries.
How does DeepSeek’s MoE architecture impact scalability and performance in real-world applications?
DeepSeek’s Mixture-of-Experts (MoE) architecture profoundly impacts scalability and performance in real-world applications by introducing a dynamic and resource-efficient approach to AI model operation. Unlike traditional dense models that activate all parameters for every task, DeepSeek’s MoE selectively engages only the most relevant subsets of its parameters, or “experts,” for each input. This targeted activation minimizes computational overhead, enabling the model to handle complex tasks with exceptional precision while conserving resources.
In terms of scalability, the modular design of the MoE architecture allows enterprises to adapt the model to diverse workloads without requiring extensive hardware upgrades. This flexibility is particularly beneficial for businesses operating in resource-constrained environments, as it ensures high performance even on standard hardware. Additionally, the architecture’s ability to process multiple tokens simultaneously enhances throughput, making it ideal for applications requiring real-time decision-making, such as financial fraud detection or supply chain optimization.
Performance-wise, the MoE framework ensures that each task benefits from specialized expertise, resulting in higher accuracy and faster inference times. By dynamically routing data to the most suitable experts, the architecture reduces latency and improves the model’s ability to handle nuanced, domain-specific challenges. This combination of scalability and performance positions DeepSeek as a transformative solution for enterprises seeking to deploy AI at scale while maintaining operational efficiency and cost-effectiveness.
What are the compliance and data privacy considerations when deploying DeepSeek in regulated industries?
Deploying DeepSeek in regulated industries necessitates a thorough understanding of compliance and data privacy considerations to ensure adherence to stringent legal and ethical standards. One critical aspect is data residency, as many industries, such as healthcare and finance, operate under regulations like GDPR, HIPAA, or the US Data Regulation, which mandate that sensitive data must remain within specific geographic boundaries. DeepSeek addresses this challenge through hybrid deployment models, allowing enterprises to process data locally while leveraging the model’s capabilities, thereby mitigating risks associated with cross-border data transfers.
Another key consideration is the transparency of AI decision-making, which is essential for compliance in sectors requiring explainability, such as legal and financial services. DeepSeek’s real-time reasoning capabilities, enabled by its test-time compute (TTC) mechanism, provide clear insights into how decisions are made, fostering trust and meeting regulatory demands for accountability.
Additionally, DeepSeek’s data handling practices must align with privacy laws to prevent unauthorized access or misuse of sensitive information. While the platform employs advanced encryption and de-identification techniques, enterprises must conduct comprehensive data risk assessments to ensure these measures meet the specific requirements of their regulatory environment. For instance, the US Data Regulation emphasizes the need for robust safeguards against unauthorized access by foreign entities, which may necessitate additional security controls when using DeepSeek.
Finally, organizations must establish clear governance frameworks to monitor and audit AI deployments, ensuring ongoing compliance as regulations evolve. By addressing these considerations, enterprises can confidently integrate DeepSeek into their operations while safeguarding data privacy and maintaining regulatory compliance.
How can enterprises effectively transition from legacy AI systems to DeepSeek’s innovative models?
Transitioning from legacy AI systems to DeepSeek’s innovative models requires a strategic, phased approach that balances technical modernization with organizational readiness. The first step involves conducting a comprehensive assessment of existing infrastructure to identify compatibility gaps. DeepSeek’s models, while optimized for efficiency, often require modern compute environments to function effectively. Enterprises must evaluate whether their current hardware and software can support the deployment or if upgrades, such as adopting Commercial Off-The-Shelf (COTS) hardware, are necessary to facilitate the transition.
Next, data harmonization becomes a critical focus. Legacy systems often operate with fragmented or siloed data, which can hinder the performance of advanced AI models like DeepSeek. Enterprises should invest in schema mapping and data quality measures to ensure consistency and enrich insights. This step not only enhances the model’s effectiveness but also streamlines integration across multiple data sources.
Building cross-functional teams is another essential component of the transition. DeepSeek’s innovative architecture, such as its Mixture-of-Experts (MoE) framework, demands specialized expertise in AI/ML to fully leverage its capabilities. Enterprises should prioritize upskilling their workforce or collaborating with external experts to bridge talent gaps. This ensures that the deployment translates into tangible business benefits rather than theoretical efficiencies.
Finally, a pilot-first approach can mitigate risks and build confidence in the new system. By deploying DeepSeek in a controlled environment, enterprises can measure its impact on specific use cases, such as enhancing enterprise search or automating customer support. Insights gained from these pilots can inform broader rollouts, ensuring a smoother transition and maximizing ROI. Through careful planning and execution, enterprises can effectively modernize their AI capabilities and unlock the full potential of DeepSeek’s innovative models.
What are the potential risks and limitations of adopting DeepSeek for critical business operations?
Adopting DeepSeek for critical business operations introduces several potential risks and limitations that enterprises must carefully evaluate to ensure successful deployment. One significant concern is data privacy and security. DeepSeek’s open-source nature and its data processing policies, particularly its reliance on servers in China, raise questions about compliance with stringent data protection regulations like GDPR or CCPA. Sensitive information could be exposed to vulnerabilities, including unauthorized access or government-mandated data sharing, which could compromise business operations in regulated industries.
Another limitation lies in the platform’s current lack of diverse third-party integrations and development tools. Unlike more established AI providers, DeepSeek requires additional customization efforts to align with specific enterprise needs. This can increase the time and resources required for deployment, particularly for businesses with complex operational requirements or legacy systems.
Geopolitical factors also pose a risk, as DeepSeek’s Chinese origins may lead to restrictions or scrutiny in certain markets, such as the U.S. or EU. These geopolitical tensions could limit accessibility or create uncertainties around long-term support and updates, making it challenging for enterprises to rely on DeepSeek for mission-critical operations.
Additionally, cybersecurity vulnerabilities, such as susceptibility to prompt injections or cross-site scripting (XSS) attacks, could expose organizations to risks like data manipulation or leaks. Enterprises must implement robust monitoring and security protocols to mitigate these threats.
Finally, the talent shortage in AI/ML expertise presents a barrier to fully leveraging DeepSeek’s advanced capabilities. Without skilled teams to manage and optimize the platform, businesses may struggle to achieve the desired outcomes, limiting the overall value of the investment. By addressing these risks and limitations proactively, enterprises can better position themselves to integrate DeepSeek into their critical business operations effectively.