
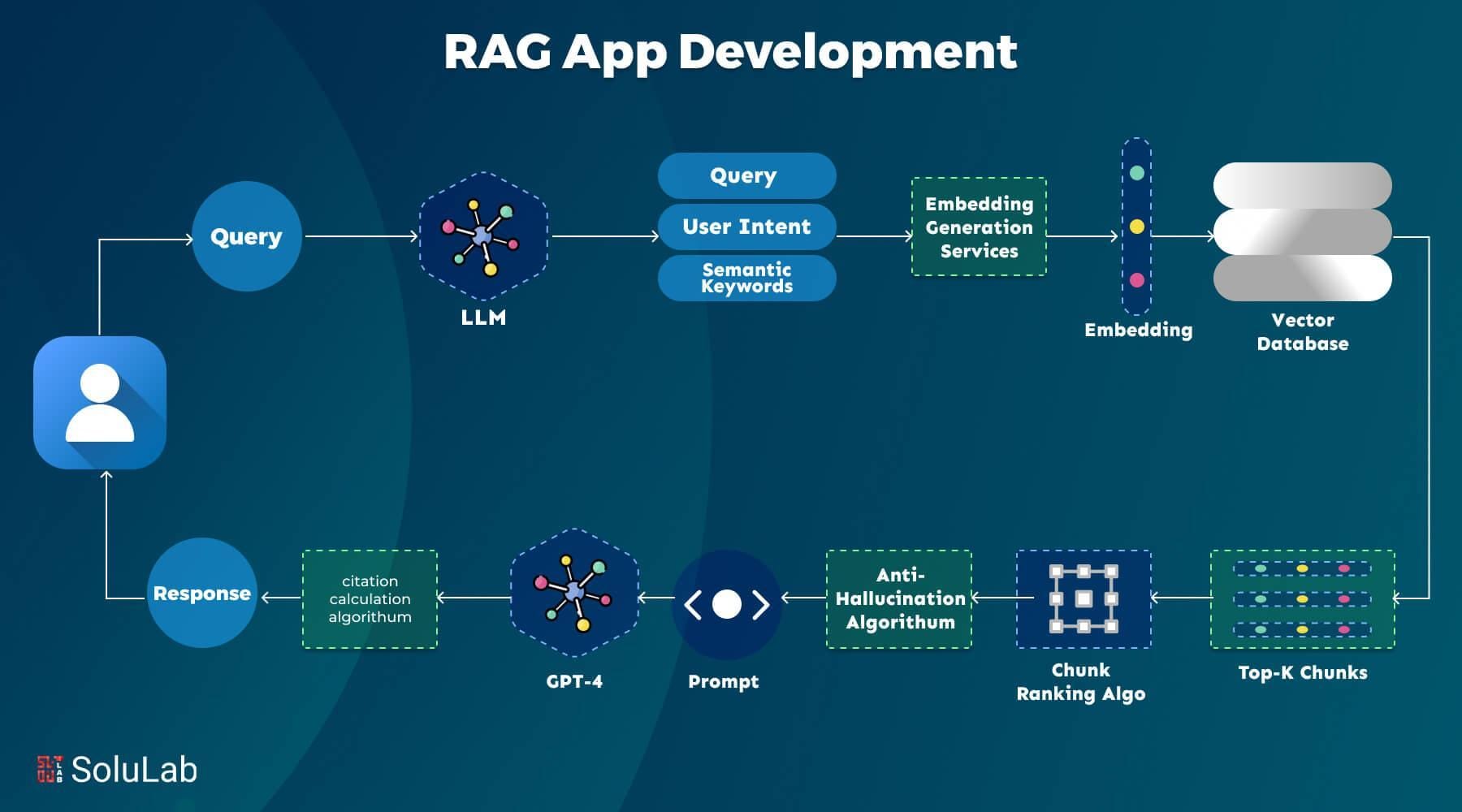
Retrieval Augmented Generation RAG Project Ideas
Explore innovative Retrieval-Augmented Generation (RAG) project ideas to enhance AI applications. From code generation and chatbots to research assistants and medical diagnosis tools, leverage RAG to improve accuracy, reasoning, and contextual understanding.


In a world overloaded with information, simply having a powerful language model isn’t always enough. Traditional models learn from static datasets and can struggle to keep up with new or fast-changing knowledge.
Retrieval Augmented Generation (RAG) tackles this problem head-on by combining two key capabilities:
- Retrieval – Pulling relevant information from external sources in real time.
- Generation – Producing coherent, context-aware text grounded in the information retrieved.
When done right, RAG systems feel less like chatbots reciting rehearsed answers and more like expert assistants capable of researching and synthesizing fresh knowledge on the fly.
Why RAG Matters
- Real-Time Updates: Unlike static models that might lag behind current events or evolving data, RAG systems actively fetch new information, keeping responses accurate and relevant.
- Contextual Depth: By drawing from large knowledge bases, these systems can handle nuanced or specialized questions, from diagnosing complex medical conditions to offering detailed legal analyses.
- Reduced Hallucination: Generative models often invent facts (known as “hallucinations”). By grounding their responses in real data, RAG systems mitigate this risk, producing more trustworthy outputs.
The result? A new wave of AI solutions that adapt and scale across a variety of domains, from e-commerce and healthcare to education and finance.
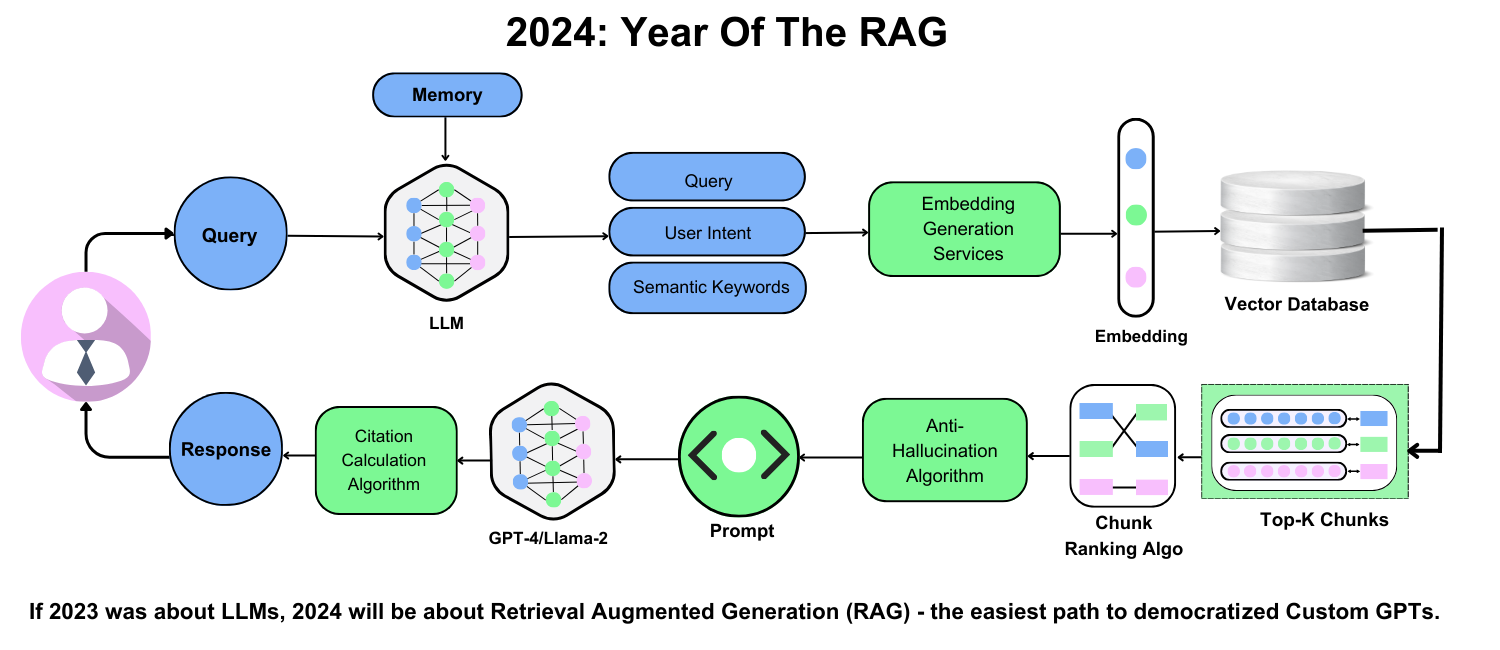
Core Concepts of RAG
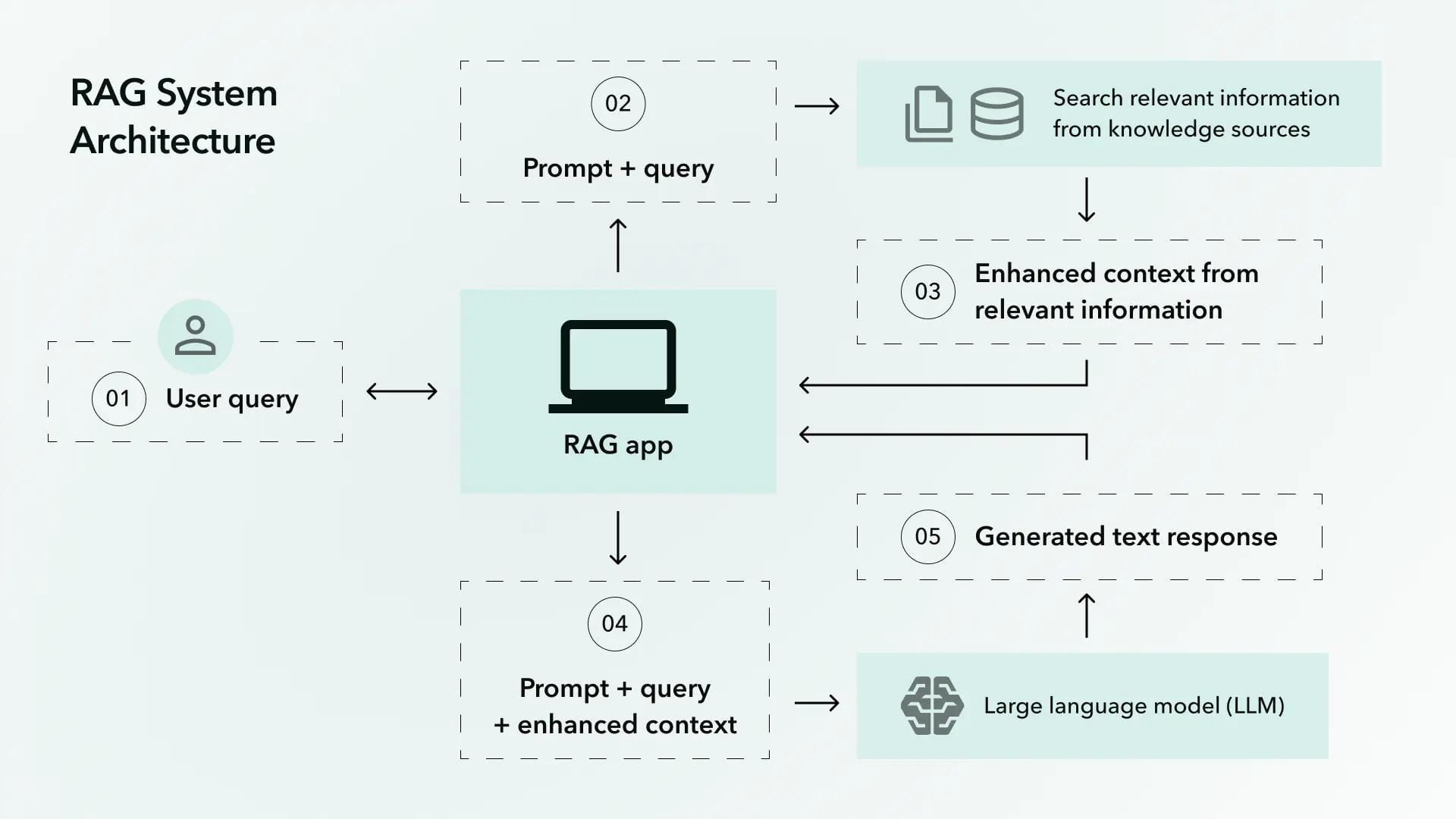
1. The Synergy Between Retrieval and Generation
RAG pairs two components:
- A Retriever that combs through external data (documents, databases, websites) to find the most relevant information.
- A Generator that uses this retrieved information to craft context-rich, accurate responses.
Think of it like a detective and a storyteller working hand in hand:
- The detective (retriever) finds clues (relevant data).
- The storyteller (generator) weaves them into a cohesive narrative (the final answer).
By linking these roles in a loop, RAG systems can refine queries based on initial retrieval results, zeroing in on increasingly precise information. This iterative approach is especially useful for complex problems—like legal research or diagnosing medical conditions—where a single round of retrieval might not be enough.
2. Tackling “Retrieval Noise”
Even the best retrievers can sometimes pull irrelevant or partially correct data, muddying the final output. This “retrieval noise” can be managed through:
- Filtering and Confidence Scoring: Assigning scores to each retrieved document based on its relevance and reliability.
- Iterative Query Refinement: Allowing the generator to tweak its queries if initial results seem off track.
For example, in healthcare, automatically discarding outdated clinical studies can ensure that generated treatment plans are both current and accurate.
3. Key Components in a RAG System
A typical RAG architecture includes three major parts:
- Retrieval Module:
- Indexing: Uses techniques like dense vector embeddings (which capture semantic meaning) alongside traditional keyword methods.
- Search: Finds the closest matches to a user’s query, filtering out irrelevant documents and prioritizing those with higher relevance scores.
- Generation Module:
- Often a transformer-based language model that integrates the retrieved facts into coherent text.
- Can use cross-attention to align relevant data with the user’s query, ensuring responses stay on topic.
- Integration/Fusion Module:
- Blends retrieved facts with generated text to produce a single, cohesive response.
- Ensures the final output is accurate, cohesive, and reads naturally.
Setting Up a RAG Development Environment
Building a robust RAG system involves more than just choosing a language model. You’ll need:
- Vector DatabaseTools like Pinecone or Weaviate store dense embeddings, enabling quick retrieval based on semantic similarity (i.e., matching meaning rather than just keywords).
- Language Model
- Smaller open-source models (like GPT-style architectures you can fine-tune) may suffice for lightweight tasks.
- For enterprise use, you might employ more powerful models fine-tuned on domain-specific data.
- Containerization & Monitoring
- Using Docker or similar tools to isolate components (retriever, generator, etc.) as microservices.
- Monitoring with Prometheus or similar tools to track performance, latency, and potential bottlenecks.
Essential Tools and Frameworks
- LangChain: A modular toolkit that connects language models to data sources, simplifying the retrieval–generation pipeline.
- Haystack: Offers an end-to-end pipeline for building search systems and RAG applications, with features like document indexing, question answering, and more.
- Vector Databases: Pinecone, Weaviate, or FAISS for managing embeddings and ensuring low-latency semantic searches.
Dataset Preparation and Management
Good data is the foundation of any successful RAG application. A few best practices:
- Metadata Optimization: Tag documents with relevant categories, timestamps, or other structured labels. This allows for more precise filtering.
- Chunking: Splitting documents into smaller pieces so the retriever can zero in on the most relevant sections.
- Regular Updates: To keep answers fresh, embeddings and indexes should be recalculated or incrementally updated when new data arrives.
Beginner-Level RAG Project Ideas
1. Personal Knowledge Assistant
A great starter project involves creating a Q&A chatbot that organizes your personal notes, bookmarks, and files into a searchable knowledge base.
Here’s how it works:
- Data Gathering: Gather your notes, PDFs, and documents, then tag them with metadata (dates, categories) for quick retrieval.
- Indexing: Use a vector database like Pinecone or a tool like FAISS to store semantic embeddings, ensuring the assistant can find relevant snippets even if your query uses different wording.
- Chat Interface: Build a simple interface (a web app or chatbot) that lets you type queries. The system retrieves matching documents and generates concise answers.It’s like having a personal librarian that never sleeps—perfect for anyone who wants a quick way to sort through years of digital clutter.
2. Smart Recipe Generator
Love cooking but hate scrolling through recipes that don’t match what’s in your fridge? This project tackles that problem:
- Ingredient-based Retrieval: Input a list of available ingredients (e.g., “broccoli, tofu, garlic”), and let the RAG system pull relevant recipes from a collection of cooking sites or a stored database.
- Tailored Generation: The system can then generate a cohesive set of instructions, modifying the recipe based on dietary preferences (vegan, gluten-free) or cooking style.
- Iterative Refinement: If you want fewer steps or a shorter prep time, the generator can refine its instructions further, making it easy to adapt to your lifestyle.
3. Basic Document Retrieval System
This is a foundational project for anyone curious about how retrieval mechanisms work under the hood:
- Indexing & Search: Set up a local or cloud-based index of documents. Dense vector embeddings help your system “understand” semantic meaning, not just keywords.
- User Interface: Create a basic search page where people type queries. The system returns the most relevant paragraphs or documents.
- Expand Gradually: As you get comfortable, add improvements like re-ranking results, filtering by date, or highlighting the sections most relevant to the query.
Intermediate RAG Project Ideas
1. Contextual Customer Support Chatbot
Companies often struggle to keep up with repetitive questions. A contextual RAG-powered chatbot goes beyond standard FAQ bots:
- User History Integration: Retrieve relevant details based on a user’s past interactions and purchases, ensuring the chatbot can provide targeted answers.
- Sentiment Detection: Pair RAG with sentiment analysis. If a user seems frustrated, the system can preemptively offer solutions or pass the conversation to a human agent.
- Adaptive Responses: Over time, the chatbot can learn from common user issues, refining both retrieval and generation to speed up resolution times.
2. Domain-Specific Knowledge Base Integration
Industries like healthcare, finance, or law need specialized systems that can parse dense, highly regulated information:
- Focused Retrieval: Pull in the latest guidelines, case studies, or regulatory documents specific to your field. For instance, a medical chatbot might retrieve peer-reviewed studies before suggesting a treatment plan.
- Summarization and Explanation: Once documents are retrieved, the generative model turns complex legal or medical text into more understandable language for non-experts.
- Compliance Checks: Integrate compliance checks to ensure the chatbot never shares confidential or unverified information.
3. Personalized News Aggregator
Keeping up with the news can be overwhelming. A RAG-based aggregator surfaces the most relevant stories for each user:
- User Behavior Analysis: Track which articles someone reads, saves, or skips to refine the retrieval process.
- Credibility and Freshness: Tag sources with credibility scores, recency, or political bias, ensuring well-rounded coverage.
- Adaptive Curation: Over time, the system learns what topics each user cares about, delivering a feed that’s both personalized and balanced.
Advanced RAG Project Ideas
1. Multimodal RAG Systems
Text alone doesn’t always paint the full picture. Multimodal RAG systems integrate text, images, and potentially audio or video:
- Healthcare Example: Retrieve and interpret patient records, lab results, and imaging data like X-rays, then generate a combined diagnostic report.
- Alignment Techniques: Use models that can map images and text to a shared vector space, enabling precise cross-referencing of visual and textual information.
- Rich Contextual Output: Outputs can highlight relevant images or timestamps in addition to text, offering a holistic view that’s extremely valuable in complex fields.
2. Voice-Integrated Virtual Assistants
Voice assistants become far more powerful when they can retrieve up-to-date information on demand:
- Real-Time Retrieval: Integrate APIs that fetch calendar events, restaurant data, weather info, or personal documents in seconds.
- Conversational Nuance: Detect the user’s mood or expertise level to adjust the depth and tone of the response.
- Hands-Free Interaction: Ideal for cooking tutorials, driving directions, or any scenario where the user can’t type.
3. Combining RAG with Reinforcement Learning
Push your system to learn from every single interaction:
- Feedback Loops: Ask users for quick thumbs-up/down or star ratings on generated answers, using this data to fine-tune retrieval strategies.
- Dynamic Adjustments: Successful results are rewarded, shaping how the model prioritizes certain data sources. Over time, the chatbot or system becomes more adept at delivering concise, relevant, and contextually rich responses.
- Scalable and Adaptive: Ideal for complex customer support, financial advisory, or educational platforms where constant updates improve user satisfaction.
Why These Ideas Matter
From personal productivity to enterprise-level automation, each of these projects illustrates a core benefit of RAG: the ability to find and generate relevant information in a way that feels dynamic, interactive, and contextually grounded. Whether you’re experimenting with a simple recipe app or building a robust, domain-specific chatbot, these ideas serve as practical examples of how RAG can be adapted to different needs and complexities.
The beauty of RAG is its flexibility. You can start with something small and fun—like generating recipes or organizing personal notes—and gradually expand into high-impact areas such as healthcare diagnostics or financial advisory. As you progress, you’ll discover new ways to combine retrieval with generation, ultimately creating solutions that feel less like static databases and more like intelligent collaborators.
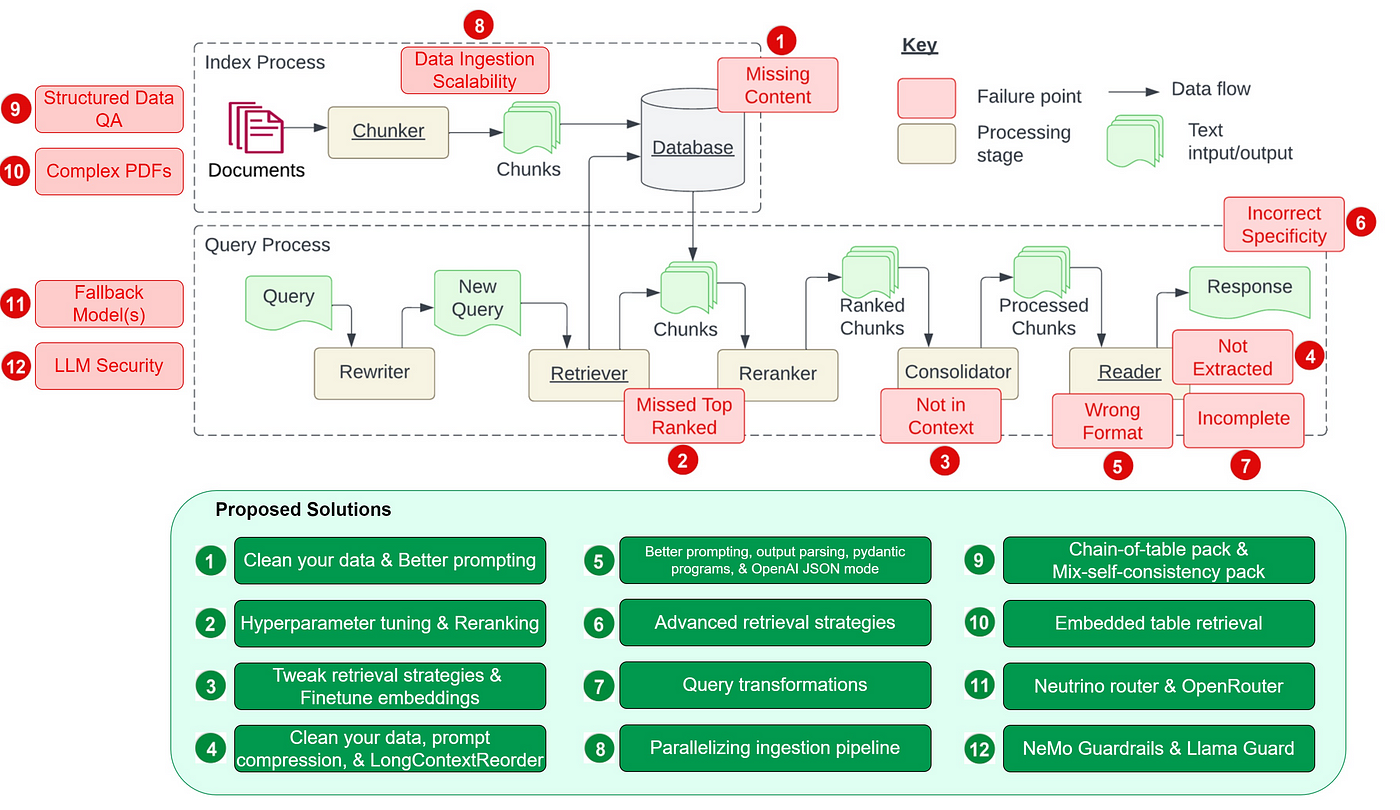
Common Challenges and How to Overcome Them
Implementing RAG isn’t always straightforward. Here are some typical hurdles and strategies to tackle them.
1. Scalability and Latency
- Issue: As data or user queries multiply, retrieval times can balloon.
- Mitigation:
- Hybrid Retrieval (combining vector-based and keyword-based searches) can balance speed and accuracy.
- Distributed Architectures spread the workload across multiple nodes or servers.
- Incremental Updates so you don’t have to re-embed everything when new data arrives.
2. Retrieval Noise
- Issue: Irrelevant or outdated data can lead to incorrect generation (“hallucinations”).
- Mitigation:
- Confidence Scoring ranks the likelihood that retrieved passages are truly relevant.
- Filtering Based on Metadata (timestamps, source credibility) to ensure fresh and reliable inputs.
- Iterative Refinement where the generator re-checks retrieved data to confirm it aligns with user queries.
3. Bias in Retrieved or Generated Outputs
- Issue: RAG systems inherit biases present in their training data or knowledge base.
- Mitigation:
- Regular Audits to detect skew or over-representation of certain viewpoints.
- Diversity-Aware Retrieval that surfaces more balanced results.
- Explainable AI Tools to highlight how the system arrived at an answer, making it easier to spot and correct bias.
4. Data Privacy and Compliance
- Issue: Handling sensitive or regulated information (e.g., medical records, financial data) can be fraught with legal and ethical concerns.
- Mitigation:
- Access Control using role-based permissions for retrieval.
- Federated Learning so data remains with the local host and only aggregated insights are shared.
- Context-Aware Masking that hides or encrypts sensitive fields without sacrificing overall relevance.
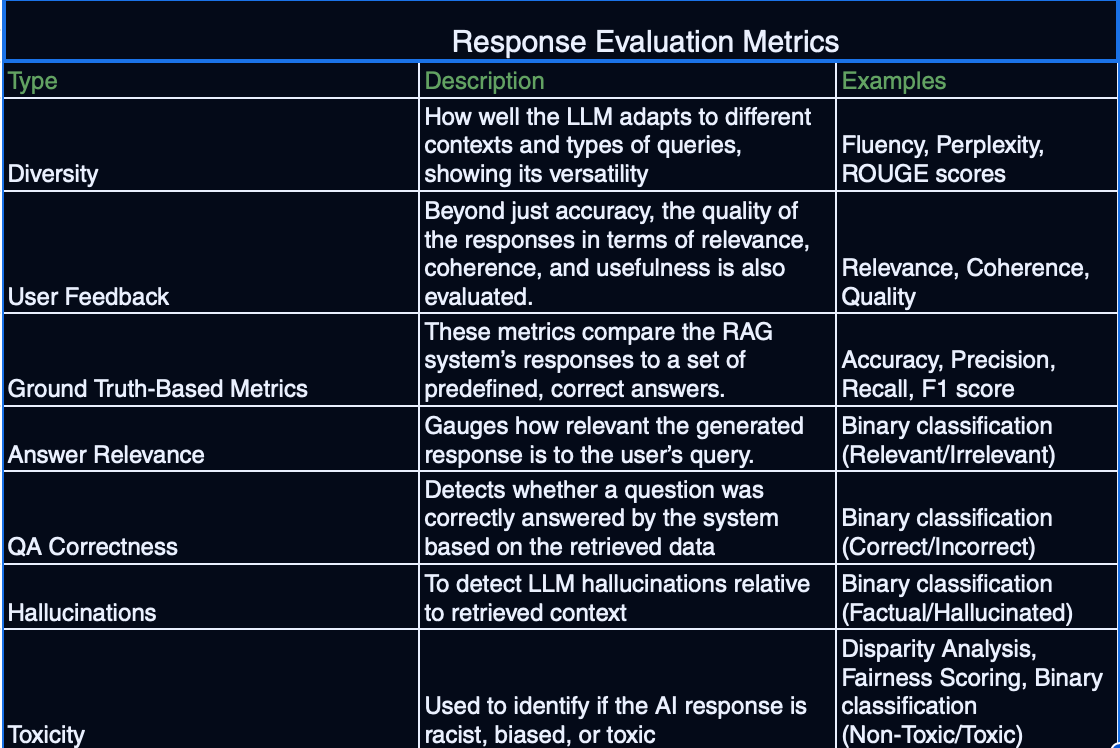
Evaluation Metrics for RAG Systems
Evaluation and Metrics
Building a RAG system is one thing; ensuring it works well over time is another. Effective evaluation often includes:
- Retrieval Accuracy
- Hit Rate, Mean Reciprocal Rank (MRR), or other domain-specific metrics that measure how quickly relevant documents appear among the top results.
- Tracking embedding drift (when embeddings become outdated) to decide when re-indexing is necessary.
- Generation Quality
- Factual Consistency: Check that the final output aligns with the retrieved data.
- Coherence: Measure how logically and fluently the response is structured.
- User-Focused Metrics: Thumbs-up/down or star ratings in user interfaces help gather quick feedback.
- User Experience and Feedback Integration
- Implicit Feedback (like click-through rates or time on page) can reveal how relevant and helpful responses are.
- Explicit Feedback (like upvotes or text comments) provides direction for targeted improvements.
- Clustering Feedback: Grouping similar complaints or suggestions helps prioritize which fixes or features to roll out first.
Cross-Domain Applications of RAG
1. Healthcare: Clinical Decision Support
By integrating patient records, medical research papers, and official treatment guidelines, RAG systems can generate recommendations tailored to individual patients. This approach not only saves time for doctors but also democratizes access to high-quality expertise—especially in remote or under-resourced areas.
2. Education: Adaptive Learning
RAG-based tutoring platforms deliver personalized lessons by analyzing a student’s performance and retrieving the most relevant practice materials. Over time, the system refines its queries to match individual progress, offering a highly adaptive learning environment.
3. Finance: Intelligent Advisory
Financial advisors can use RAG to pull in real-time market data, regulatory updates, and economic forecasts. This data, combined with a user’s personal risk profile, helps craft more accurate investment suggestions. In a space where milliseconds can matter, a well-tuned RAG system can give professionals a critical edge.
FAQ
What is Retrieval Augmented Generation (RAG) and how does it enhance traditional language models?
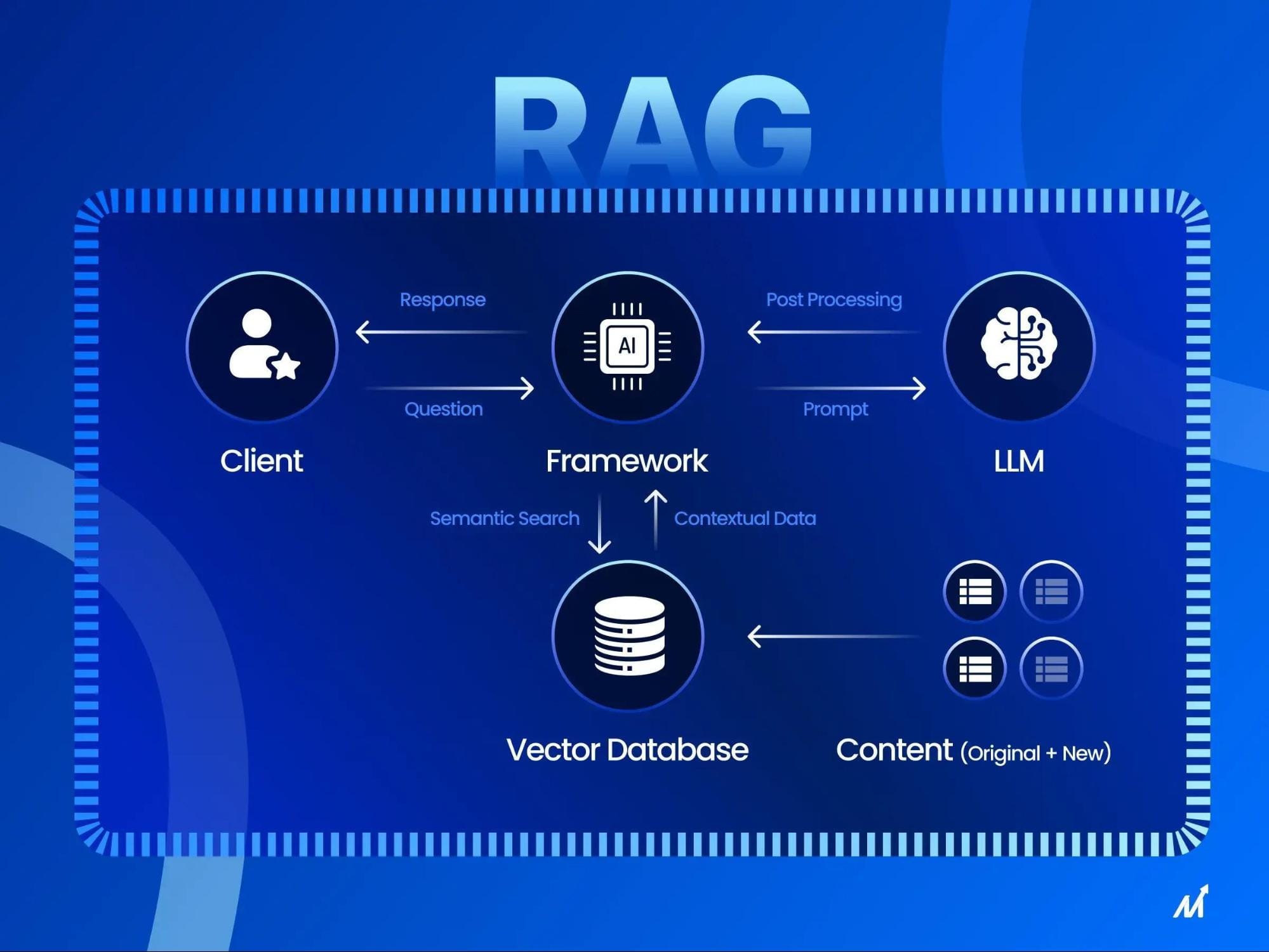
Retrieval Augmented Generation (RAG) is a cutting-edge approach that combines the strengths of retrieval-based and generative AI models to overcome the limitations of traditional language models.
Unlike conventional models that rely solely on pre-trained parameters, RAG dynamically retrieves relevant information from external sources, such as databases or knowledge bases, during the generation process. This integration allows RAG to provide more accurate, contextually relevant, and up-to-date responses.
By leveraging external knowledge, RAG enhances the adaptability and factual accuracy of language models, making them more effective for knowledge-intensive tasks like question answering, content generation, and decision support.
What are the key components required to build a RAG system for practical applications?
The key components required to build a RAG system for practical applications include the Retriever, the Generator, and the Fusion Module. The Retriever is responsible for identifying and extracting the most relevant information from external data sources, such as databases, documents, or the web, using techniques like dense vector retrieval or hybrid approaches to ensure semantic relevance.
The Generator takes the retrieved information and integrates it into the natural language generation process, producing coherent and contextually accurate responses. The Fusion Module acts as the intermediary, aligning the retrieved data with the user query and ensuring seamless integration into the generated output.
Together, these components enable RAG systems to deliver factually grounded and linguistically fluent responses, making them highly effective for real-world applications.
How can RAG be implemented in real-world projects, and what are some beginner-friendly ideas?
RAG can be implemented in real-world projects by integrating retrieval mechanisms with pre-trained language models to enhance their ability to generate accurate and contextually relevant outputs. This involves setting up a retrieval module to access external knowledge sources, such as vector databases, and combining it with a generative model to produce responses grounded in real data.
For beginners, some project ideas include building a personalized FAQ bot that dynamically retrieves and answers user queries, creating a smart recipe generator that tailors recipes based on user preferences, or developing a document summarization tool that condenses lengthy texts into concise summaries. These projects provide a practical introduction to RAG while addressing common use cases in various domains.
What tools and frameworks are recommended for developing RAG-based solutions?
Tools and frameworks recommended for developing RAG-based solutions include vector databases like Pinecone and Weaviate, which enable efficient storage and retrieval of dense embeddings. Frameworks such as Haystack and Hugging Face’s RAG model provide end-to-end pipelines for integrating retrieval and generation capabilities.
LangChain is another valuable tool, offering modular components to connect language models with external data sources seamlessly. Additionally, platforms like IBM Watsonx.ai and Meta AI provide advanced RAG implementations tailored for specific use cases. These tools and frameworks simplify the development process, making it easier to build robust and scalable RAG-based applications.
What are the common challenges in RAG implementation, and how can they be mitigated?
Common challenges in RAG implementation include scalability, retrieval quality, and seamless integration between retrieval and generation components. Scalability issues arise when handling large and dynamically growing datasets, which can be mitigated by employing hybrid retrieval methods and distributed architectures to optimize performance.
Retrieval quality challenges, such as irrelevant or outdated information, can be addressed through metadata tagging, regular updates to embeddings, and contextual filtering. Ensuring smooth integration between retrieval and generation requires preprocessing retrieved data to align with the generator’s input format and leveraging jointly fine-tuned models for better coherence.
By proactively addressing these challenges, developers can enhance the efficiency and reliability of RAG systems in practical applications.
Conclusion
Building a RAG system isn’t just about combining retrieval and generation—it’s about creating a seamless conversation between data and context. Think of it like assembling a team: the retriever is the researcher, the generator is the storyteller, and the fusion module is the editor ensuring everything flows. When these roles align, the results are transformative.
For example, a beginner project like a personalized FAQ bot can evolve into a dynamic customer support tool, reducing response times by up to 40% (as seen in enterprise case studies). But here’s the catch: messy data can derail even the best systems. That’s why metadata optimization and regular updates are non-negotiable.
A common misconception? That RAG is only for tech giants. In reality, open-source tools like LangChain and Pinecone make it accessible to anyone with a laptop and curiosity. Start small, iterate, and watch your ideas scale.