
What is RAG API and How Does it Work?
This guide explores the RAG API, its functionality, key components, and practical applications, providing a clear understanding of how it enhances AI-driven retrieval and generation.


Imagine an AI system that not only generates text but also pulls in real-time, contextually relevant data to enhance its responses. Sounds like science fiction, right? Yet, this is precisely what Retrieval-Augmented Generation (RAG) APIs achieve. While traditional AI models often stumble when faced with outdated or incomplete information, RAG APIs bridge this gap by dynamically integrating external knowledge into their outputs.
Why does this matter now? As businesses and developers race to create smarter, more reliable AI applications, the demand for systems that can adapt to ever-changing information landscapes has never been higher. RAG APIs are not just a technical upgrade—they represent a paradigm shift in how we think about AI’s role in decision-making, customer engagement, and even creativity.
But here’s the real question: how does this seamless blend of retrieval and generation actually work? And what does it mean for the future of AI-driven solutions? Let’s explore.
The Evolution of AI and the Need for Advanced Retrieval
AI’s evolution has been marked by a persistent challenge: balancing generative creativity with factual accuracy. Traditional models, while impressive in generating human-like text, often falter when tasked with providing up-to-date or domain-specific information. This limitation stems from their reliance on static training data, which quickly becomes outdated in fast-moving fields like finance, healthcare, and law.
Enter advanced retrieval mechanisms. By integrating real-time data retrieval into generative processes, RAG APIs address this gap. For instance, IBM Watson leverages RAG to assist doctors by retrieving the latest medical research, ensuring diagnoses are informed by cutting-edge knowledge. Similarly, Google’s search engine uses retrieval-augmented techniques to deliver precise, context-aware answers to complex queries.
Advanced RAG systems don’t just retrieve data—they evaluate its relevance, discarding noise to enhance response quality. This approach challenges the assumption that “more data equals better results,” proving that precision often trumps volume. Looking ahead, refining these retrieval strategies will be key to unlocking AI’s full potential in decision-critical applications.
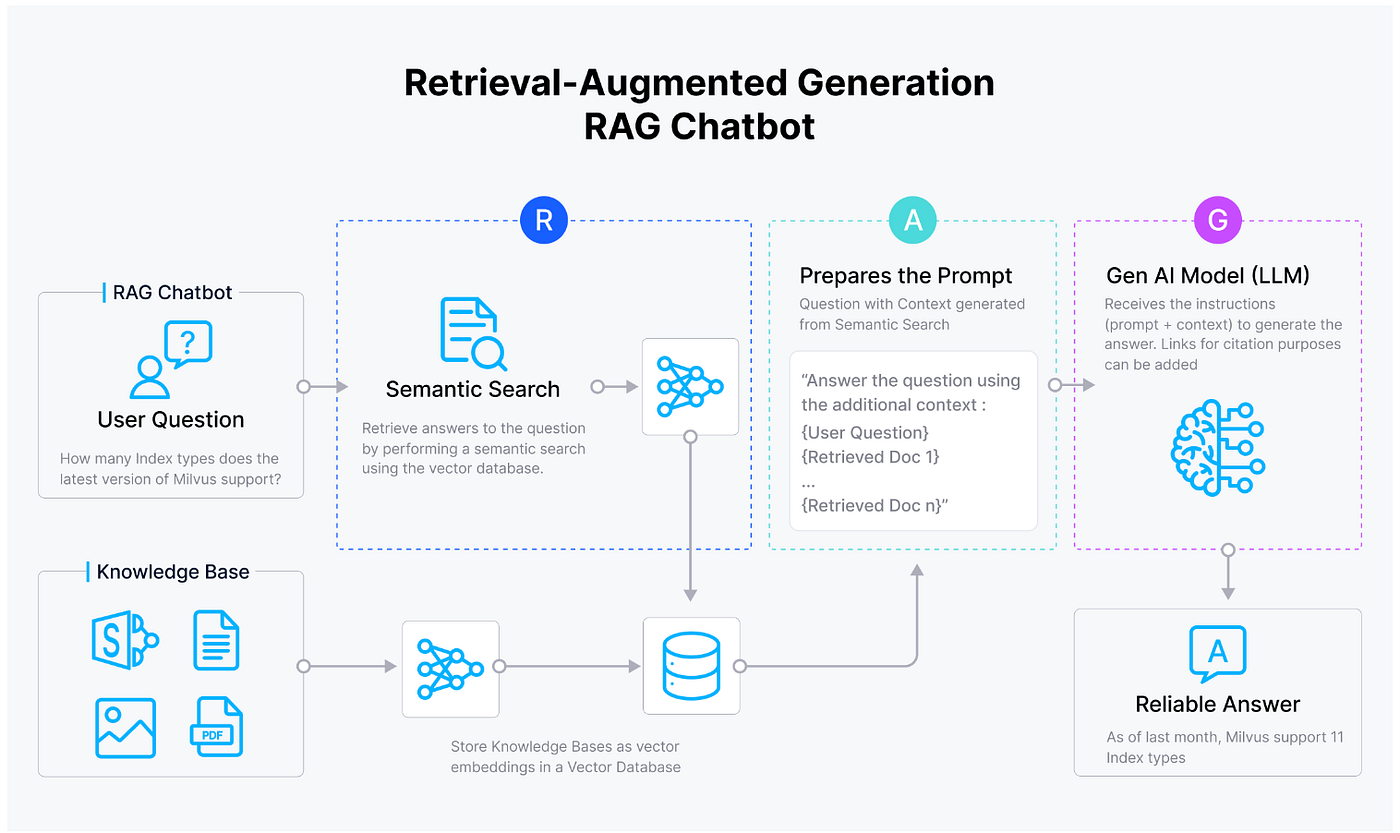
Overview of Retrieval-Augmented Generation (RAG)
RAG combines a retrieval mechanism with generative capabilities, enabling accurate and contextually relevant outputs by pulling up-to-date data from external sources. This dual-layer approach excels in areas requiring precision, such as customer service, where RAG can generate personalized responses by accessing live databases, past interactions, and product documentation. By focusing on meaning rather than keywords, RAG retrieves data that closely aligns with user intent.
RAG integrates retrieval precision with generative fluency, using dense vector embeddings to find relevant data and synthesize it into coherent responses. This process is transforming industries like healthcare, legal services, and e-commerce by ensuring real-time, accurate, and actionable outputs. By leveraging semantic search and NLP advancements, RAG continues to redefine AI-driven communication.
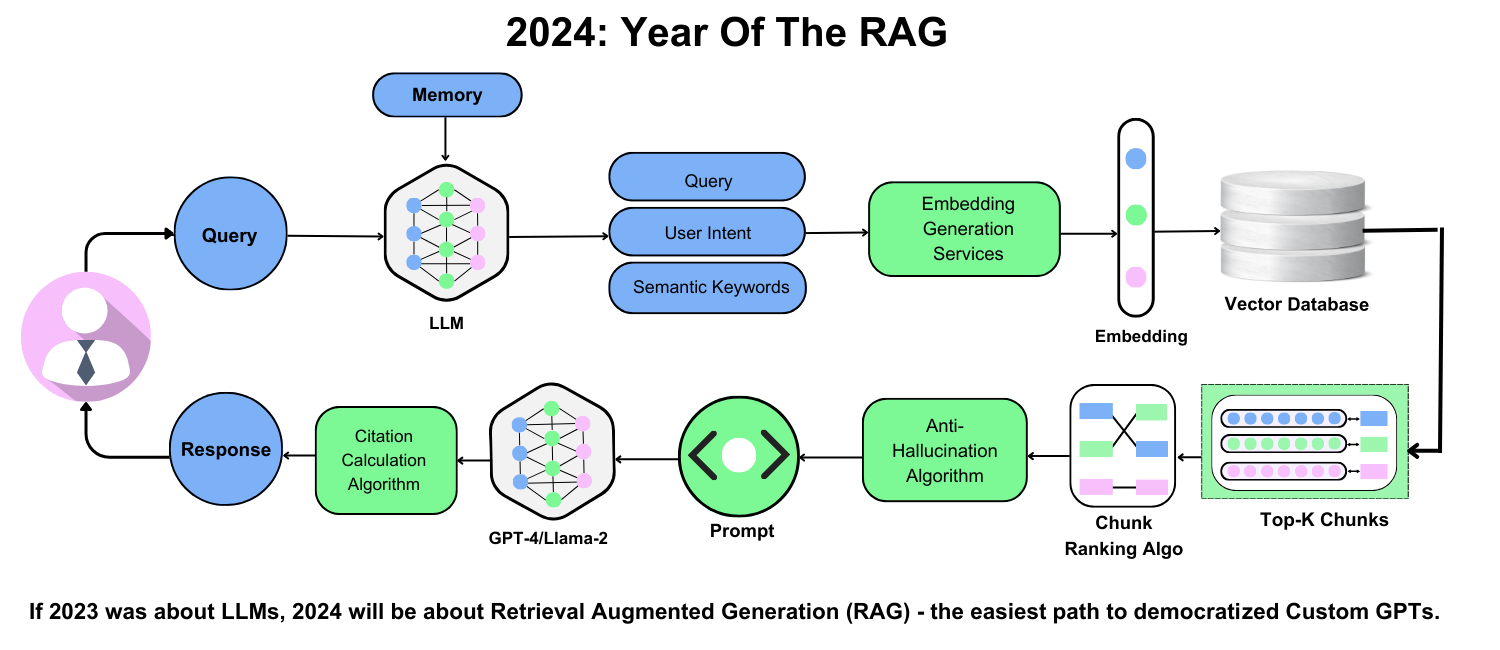
How RAG Enhances AI Capabilities
RAG transforms AI capabilities by addressing the hallucination problem—a common issue where models generate plausible but incorrect information. By grounding responses in real-time, external data, RAG ensures outputs are factually accurate and contextually relevant. This is particularly impactful in high-stakes domains like healthcare, where RAG can retrieve the latest clinical guidelines to support diagnostic tools.
RAG enhances personalization by dynamically pulling user-specific data (e.g., purchase history) to craft tailored responses, boosting user satisfaction. This bridges the gap between static AI models and the demand for adaptive, real-world applications.
Interestingly, RAG’s reliance on semantic search introduces challenges in data bias and retrieval quality. Addressing these requires robust evaluation frameworks and diverse training datasets. Moving forward, integrating RAG with multimodal systems—combining text, images, and audio—could unlock even richer, more intuitive AI interactions.
The Role of Retrieval in Language Models
Retrieval acts as the foundation of RAG systems, enabling language models to access real-time, domain-specific knowledge. Unlike static training data, retrieval mechanisms dynamically fetch relevant information, ensuring outputs remain accurate and contextually grounded. For example, in legal research, retrieval models can extract case law from vast databases, allowing generative models to synthesize precise legal arguments.
Techniques like vector indexing, which captures semantic meaning, outperform traditional keyword-based methods in understanding user intent. However, hybrid indexing—combining semantic and exact-match approaches—often yields the best results, especially in complex queries.
Retrieval also intersects with disciplines like information retrieval and knowledge graphs, offering opportunities for deeper integration. To optimize outcomes, organizations should invest in fine-tuning retrieval algorithms for their specific use cases. Looking ahead, advancements in retrieval efficiency could redefine how AI systems handle large-scale, real-time data.
Introducing RAG API
The RAG API is a game-changer, seamlessly merging retrieval systems with generative AI to deliver contextually accurate, real-time responses. Think of it as pairing a seasoned researcher with a creative writer—one finds the facts, the other crafts the narrative. This synergy addresses a major flaw in traditional AI: reliance on outdated, static training data.
For instance, in e-commerce, a RAG API can dynamically generate product recommendations by pulling live inventory data and blending it with user preferences. This not only enhances personalization but also reduces cart abandonment rates, a $260 billion problem globally.
RAG APIs synthesize information, creating outputs that are both precise and nuanced, rather than just acting as faster search engines. Experts emphasize the importance of retrieval quality, as poor indexing can derail even the most advanced systems. By bridging retrieval and generation, RAG APIs redefine how AI interacts with dynamic data landscapes.
Core Components and Architecture
At the heart of a RAG API lies the retrieval mechanism, which uses dense vector embeddings to locate relevant data. Unlike keyword-based search, this approach captures semantic meaning, enabling the system to fetch contextually accurate information. For example, in healthcare, it can retrieve the latest treatment protocols by understanding nuanced medical queries, not just matching terms.
The generative engine then transforms this data into coherent, user-friendly outputs. This step is where creativity meets precision, as the engine must balance factual accuracy with conversational fluency. A poorly tuned generative model risks introducing “hallucinations,” where outputs deviate from the retrieved data.
The ingestion engine integrates enterprise content connectors to ensure only trusted, high-quality data enters the system. This safeguards against biases and inaccuracies, especially in regulated industries like finance.
To future-proof RAG systems, organizations should prioritize modular architectures, enabling seamless updates as data sources evolve.
Key Features and Functionalities
One standout feature of RAG APIs is advanced chunking, which breaks large datasets into smaller, contextually meaningful segments. This ensures that retrieval systems can process and prioritize relevant information efficiently. For instance, in legal tech, advanced chunking allows AI to extract specific clauses from lengthy contracts, saving hours of manual review.
By supporting diverse formats like PDFs, CSVs, and even multimedia, RAG APIs enable seamless integration across industries. A real-world example is in education, where RAG systems ingest video lectures and accompanying transcripts to provide students with tailored study materials.
Tagging content with attributes like author, date, and relevance, RAG APIs enhance retrieval precision. This is particularly valuable in research, where outdated or irrelevant data can skew results.
To maximize these features, organizations should invest in robust preprocessing pipelines and metadata strategies.
Supported Platforms and Integrations
RAG APIs seamlessly integrate with platforms like Google Drive, Notion, and Confluence, unifying fragmented data into a single, searchable knowledge base. For example, a product team can instantly retrieve insights from meeting notes stored in Notion while cross-referencing technical specs in Confluence.
What sets RAG APIs apart is their ability to handle dynamic data environments. Unlike traditional systems, they adapt to real-time updates, ensuring that retrieved information reflects the latest changes. In cloud management, this means pulling live metrics from AWS or Azure to optimize resource allocation without manual intervention.
Adhering to RESTful principles, RAG APIs simplify integration across legacy systems, reducing development overhead. To fully leverage these integrations, teams should prioritize API-first design strategies and invest in scalable infrastructure.
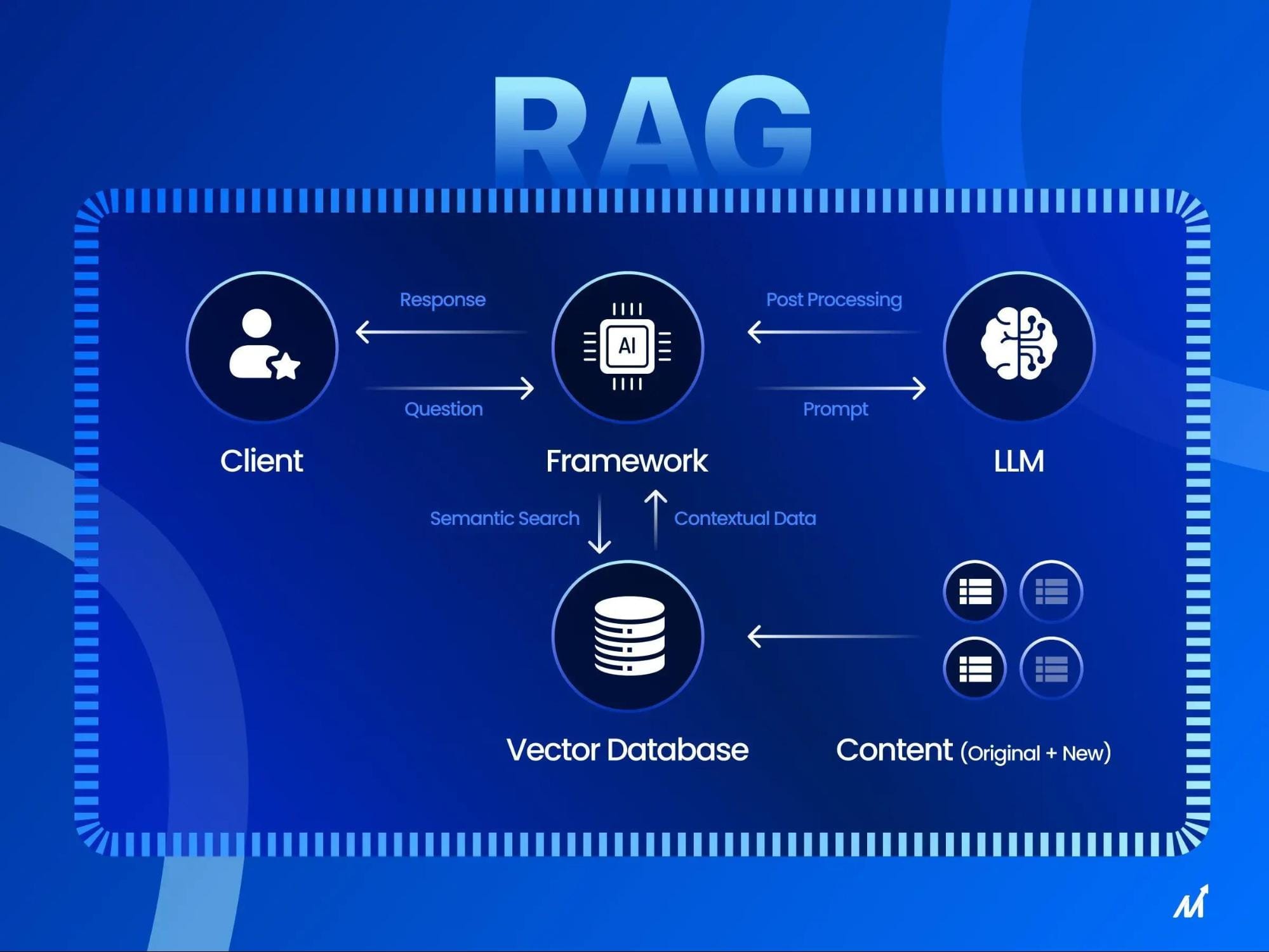
How Does RAG API Work?
RAG API operates by combining retrieval systems with generative AI models to deliver precise, context-aware responses. Think of it as a librarian and a storyteller working in tandem: the librarian fetches the most relevant books (data), while the storyteller crafts a narrative (response) tailored to your needs. This synergy ensures outputs are both accurate and engaging.
The process begins with a retrieval mechanism that uses dense vector embeddings to locate relevant data from external sources. For instance, a healthcare application might pull the latest clinical guidelines from a medical database. This retrieved data is then passed to a generative language model, like GPT, which synthesizes it with user prompts to create a coherent response.
RAG synthesizes insights, bridging gaps between static knowledge and dynamic information. This makes it invaluable for industries like finance, where real-time accuracy is critical.
Data Retrieval and Processing Mechanisms
The success of a RAG API hinges on its ability to retrieve contextually relevant data efficiently. This starts with dense vector embeddings, which map queries and documents into a shared semantic space. Unlike traditional keyword searches, this approach captures the meaning behind user prompts, enabling retrieval systems to surface nuanced, high-value information. For example, in e-commerce, this mechanism can match vague customer queries like “eco-friendly office chairs” to specific product listings with detailed sustainability certifications.
Techniques like tokenization, stemming, and stop-word removal streamline raw data into digestible formats for the generative model. However, lesser-known factors, such as the biases in training datasets, can skew retrieval results. Addressing this requires diverse, well-structured data sources and regular audits.
Looking ahead, integrating knowledge graphs with retrieval systems could further enhance precision by embedding domain-specific relationships, offering richer, more actionable insights across industries.
Interaction Between Retrieval and Generation Modules
The synergy between retrieval and generation modules is the backbone of RAG systems, with retrieval precision directly influencing generative output quality. A critical yet underexplored aspect is the feedback loop between these modules. When the generation module identifies gaps or ambiguities in retrieved data, iterative retrieval can refine results, ensuring responses are both accurate and contextually rich. For instance, in legal tech, this loop enables chatbots to clarify complex statutes by retrieving supplementary case law.
Over-retrieval can overwhelm the generation module, leading to diluted or contradictory outputs. Techniques like query expansion—where user prompts are semantically enriched—help narrow retrieval scope without sacrificing depth.
Cross-disciplinary insights from human cognition suggest that layering retrieval hierarchies, akin to how humans prioritize information, could further optimize this interaction. Future systems might incorporate adaptive retrieval strategies, dynamically adjusting based on the generation module’s evolving needs.
Workflow Example: From Query to Response
Query intent classification ensures the system routes user prompts to the most relevant retrievers, optimizing response accuracy. For example, in e-commerce, a query like “Is this product available in red?” triggers a retriever focused on inventory data, while “What are the product’s features?” activates a retriever linked to product descriptions. Misclassification here can lead to irrelevant or incomplete responses, frustrating users.
To enhance this process, multi-layered retriever hierarchies can be employed. These hierarchies prioritize retrievers based on query complexity, ensuring simpler queries are resolved faster while reserving computationally intensive retrievers for nuanced prompts.
Parallels can be drawn to decision trees in machine learning, where branching logic improves efficiency. By integrating user feedback loops, RAG systems can refine intent classification over time, paving the way for more adaptive and precise workflows.
Implementing RAG API: A Step-by-Step Guide
To implement a RAG API effectively, start by defining your data ingestion pipeline. Think of this as building a library: you need to curate high-quality, domain-specific content. For instance, a healthcare application might prioritize clinical guidelines and peer-reviewed studies. Neglecting this step often leads to irrelevant or biased outputs, undermining user trust.
Next, focus on vector embedding optimization. This is where the magic happens—transforming raw data into searchable, semantic representations. A retail platform, for example, can use embeddings to match vague customer queries like “shoes for rainy weather” with waterproof footwear. Fine-tuning these embeddings ensures precision and relevance.
Much like a GPS recalibrates based on traffic, RAG APIs improve by learning from user interactions. A case study in legal tech showed that incorporating user corrections reduced retrieval errors by 30%, streamlining case preparation.
By treating implementation as an iterative process, you unlock the full potential of RAG APIs.
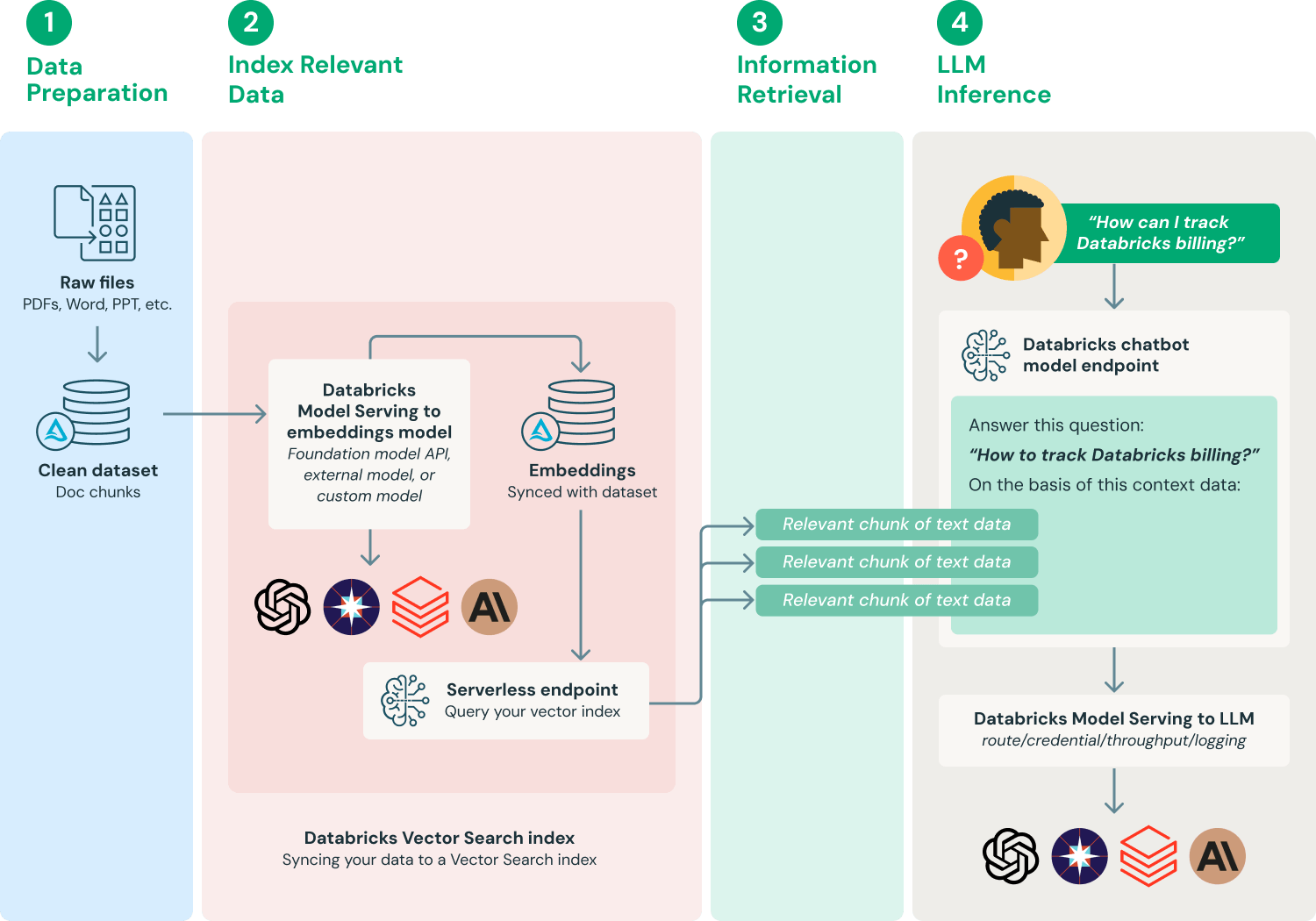
Setting Up the Development Environment
The cornerstone of a successful RAG API implementation lies in choosing the right infrastructure. Start by selecting a scalable cloud platform—AWS, Azure, or GCP—to handle the computational demands of real-time retrieval and generation. For example, a financial services firm using AWS Lambda reduced latency by 40% during peak trading hours, ensuring seamless user experiences.
Next, prioritize containerization and orchestration. Tools like Docker and Kubernetes simplify deployment, allowing you to isolate retrieval and generation modules for independent scaling. This modularity is critical in industries like e-commerce, where seasonal traffic spikes can overwhelm static systems.
Integrating ETL (Extract, Transform, Load) workflows ensures clean, structured data enters your system. A healthcare startup found that automating ETL with Apache Airflow cut manual data preparation time by 60%, accelerating model training.
By investing in robust infrastructure and automation, you future-proof your RAG API against evolving demands.
Integrating RAG API into Applications
Query intent mapping using natural language understanding (NLU) models ensures the retrieval system fetches the most relevant data by classifying user queries into predefined intents. For instance, a customer support chatbot using RAG reduced irrelevant responses by 30% after implementing intent-based routing.
Embedding domain-specific knowledge into the retrieval layer. Fine-tuning vector embeddings with industry-specific datasets—like legal documents or medical journals—enhances precision. A legal tech firm achieved 50% faster case research by integrating RAG with a custom-trained embedding model.
Real-time feedback loops can refine system performance. By capturing user interactions, such as clicks or corrections, RAG APIs can dynamically adjust retrieval priorities. This iterative improvement mirrors techniques in recommendation systems, bridging disciplines for better outcomes.
These strategies not only optimize integration but also unlock new possibilities for adaptive, user-centric applications.
Customization and Configuration Options
Adaptive chunking is a technique where data is segmented into contextually relevant pieces based on query patterns. Unlike static chunking, this approach dynamically adjusts chunk sizes to match user intent, improving retrieval accuracy. For example, a healthcare application using adaptive chunking reduced irrelevant data retrieval by 40%, enabling faster access to critical patient information.
Metadata-driven retrieval prioritization, by tagging data with relevant metadata like timestamps, geolocation, or domain-specific labels, helps RAG systems prioritize results based on user context. A supply chain platform leveraged this to rank real-time logistics data higher, cutting decision-making time by 25%.
Multi-modal integration allows RAG APIs to process diverse data types like text, images, and audio. This cross-disciplinary capability is transforming industries like education, where personalized learning paths now incorporate video and text seamlessly.
These options redefine flexibility, paving the way for more intelligent, context-aware systems.
Testing and Debugging Techniques
Synthetic query generation, by creating artificial queries that mimic real-world user behavior, helps developers stress-test retrieval mechanisms under diverse scenarios. For instance, a financial platform used synthetic queries to simulate high-frequency trading data requests, uncovering edge cases that traditional testing missed.
Trace-based debugging tracks the flow of data from retrieval to generation. This method helps pinpoint where errors occur—whether in vector embeddings, preprocessing, or generative outputs. A legal tech firm applied trace-based debugging to identify metadata mismatches, reducing response inaccuracies by 30%.
Feedback loop validation ensures that user feedback is correctly integrated into system updates. This technique, often overlooked, is vital for maintaining long-term accuracy. In e-commerce, validating feedback loops improved product recommendation precision, driving a 15% increase in conversions.
These strategies not only enhance reliability but also future-proof RAG systems for evolving demands.
Advanced Features and Optimization
Adaptive chunking dynamically segments data based on context. Think of it as slicing a pie differently depending on who’s eating—this ensures the most relevant “slice” is served to the user. For example, a healthcare application used adaptive chunking to prioritize patient-specific data, reducing retrieval time by 20% during critical diagnoses.
Another game-changer is multi-modal integration, enabling RAG systems to process text, images, and even audio seamlessly. A retail platform leveraged this to combine product descriptions with customer reviews and visual data, creating hyper-personalized recommendations that boosted sales by 18%.
Optimization isn’t just about features—it’s about balancing precision and recall. Over-prioritizing precision can miss broader insights, while excessive recall risks overwhelming users with irrelevant data. By fine-tuning vector embeddings, a legal research tool achieved a 25% improvement in case law retrieval accuracy, striking the perfect balance.
These innovations redefine what’s possible, bridging gaps across industries.
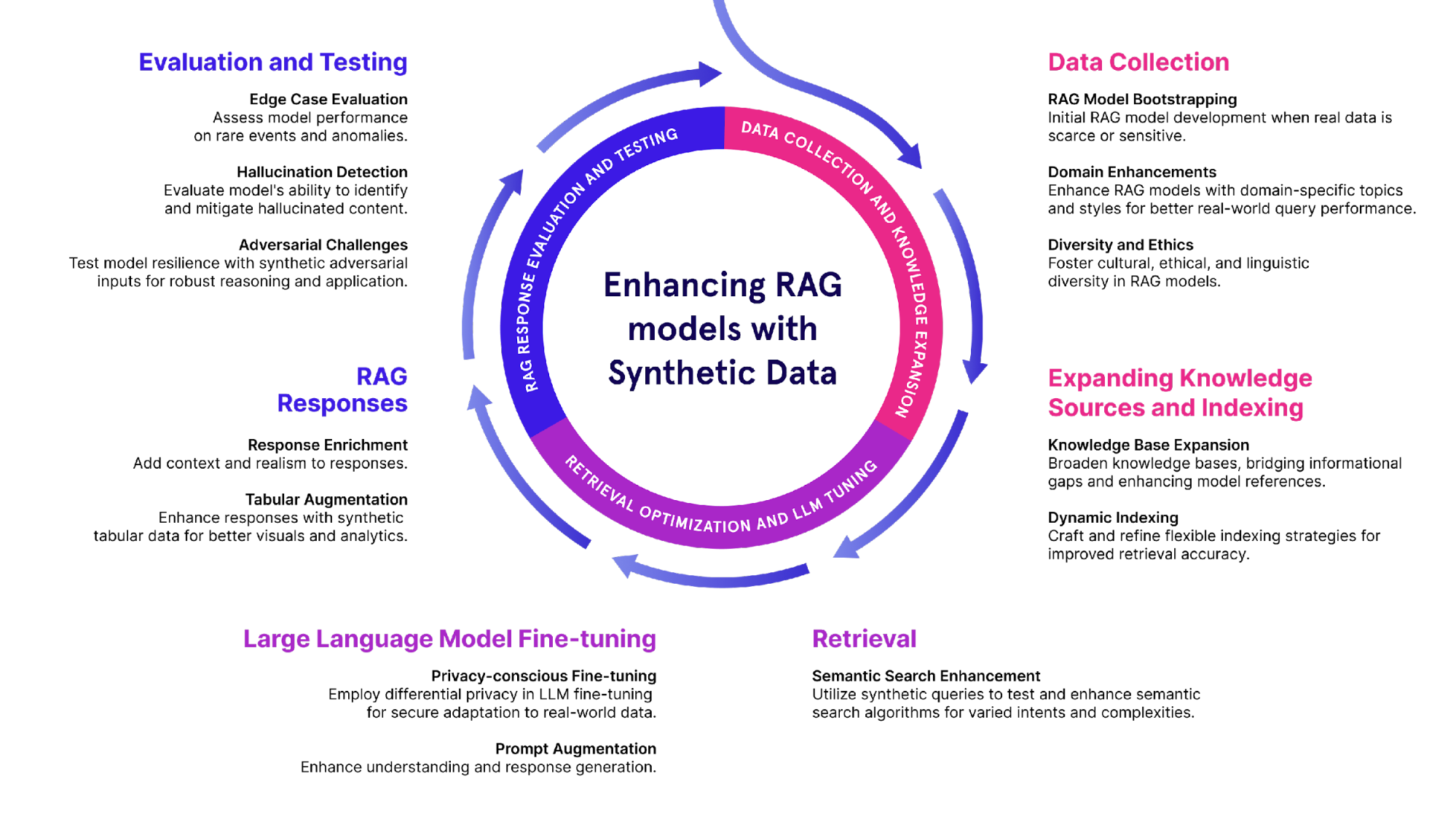
Fine-Tuning with Custom Datasets
Fine-tuning with custom datasets transforms a generic RAG system into a domain-specific powerhouse. By retraining models on curated data, you can inject nuanced expertise into the system. For instance, a financial services firm fine-tuned its RAG API with proprietary market analysis, enabling it to deliver investment insights tailored to niche sectors like renewable energy.
Clean, well-labeled data amplifies accuracy, while noisy datasets can derail performance. A healthcare startup discovered this firsthand: after refining its training data to exclude outdated medical guidelines, diagnostic accuracy improved by 30%.
Fine-tuning isn’t just about adding data; it’s about removing bias. Techniques like adversarial validation can identify and mitigate skewed patterns, ensuring fairer outputs. This approach has parallels in disciplines like ethics in AI, where transparency and accountability are paramount.
Done right, fine-tuning doesn’t just optimize—it redefines what’s possible.
Performance Tuning and Scalability
Optimizing retrieval latency is a cornerstone of performance tuning in RAG systems. Techniques like caching frequently accessed queries can reduce response times by up to 50%, as demonstrated by e-commerce platforms handling high-traffic product searches. However, over-reliance on caching risks outdated results, making cache invalidation strategies critical for maintaining accuracy.
Scalability hinges on distributed architectures. By leveraging frameworks like Kubernetes, organizations can dynamically scale retrieval and generation modules based on demand. A media company, for example, scaled its RAG API during live events, ensuring seamless user experiences despite traffic spikes.
Splitting large datasets into smaller, manageable shards improves retrieval efficiency, especially for domain-specific applications. This approach parallels database optimization techniques, where partitioning enhances query performance.
To future-proof scalability, consider adaptive load balancing. By analyzing real-time traffic patterns, systems can allocate resources intelligently, ensuring both cost-efficiency and peak performance.
Security and Compliance Considerations
Data encryption at rest and in transit is non-negotiable for RAG systems handling sensitive information. Implementing end-to-end encryption protocols, such as TLS 1.3, ensures that data remains secure during retrieval and generation processes. For instance, healthcare applications using RAG APIs must comply with HIPAA by encrypting patient data, safeguarding it from unauthorized access.
Auditability is enhanced by embedding detailed logging mechanisms, allowing organizations to trace data access and modifications, ensuring compliance with regulations like GDPR. This approach not only builds trust but also simplifies incident response by pinpointing vulnerabilities quickly.
By stripping identifiable information during preprocessing, RAG systems can mitigate privacy risks while maintaining functionality. This technique is particularly effective in industries like finance, where anonymized datasets enable fraud detection without exposing customer identities.
Real-time compliance monitoring tools can proactively flag potential violations, ensuring systems remain secure and regulation-ready.
Use Cases and Applications
RAG APIs are transforming industries by bridging static data with real-time insights. In healthcare, a major hospital network reduced misdiagnoses by 30% using RAG-powered clinical decision support systems. By integrating electronic health records and medical databases, doctors accessed precise, timely information, cutting literature review time by 25% and improving rare disease detection by 40%.
In e-commerce, RAG enhances product recommendations by analyzing live inventory, customer reviews, and seasonal trends. For example, a retail giant used RAG to reduce return rates by 15%, thanks to personalized product education and real-time inventory updates.
RAG systems retrieve case law and generate draft summaries, slashing research time while improving consistency. A law firm using domain-specific embeddings reported a 20% increase in case preparation efficiency.
These examples highlight RAG’s versatility, from improving patient outcomes to streamlining legal workflows. Its ability to synthesize dynamic data into actionable insights.
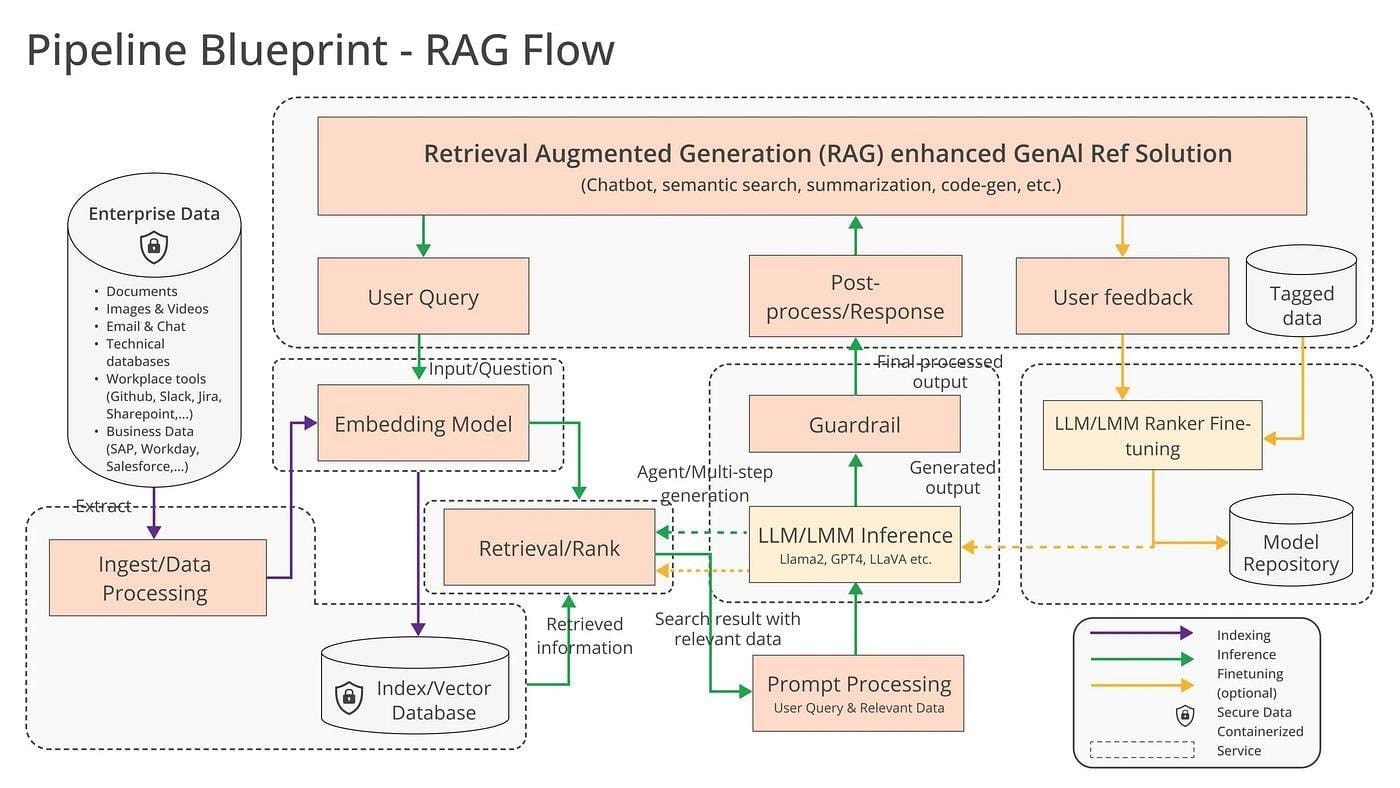
Enhancing Customer Support Systems
RAG APIs revolutionize customer support by blending retrieval precision with generative fluency, enabling systems to deliver tailored, context-aware responses. Unlike traditional chatbots that rely on static scripts, RAG-powered systems dynamically pull from live databases—product manuals, FAQs, and even past customer interactions—to craft responses that feel human and informed.
Take the example of a telecom provider. By integrating RAG, their support system resolved 40% more queries on the first attempt. The API retrieved troubleshooting guides in real-time, cross-referenced them with customer history, and generated step-by-step solutions. This not only reduced call center load but also boosted customer satisfaction scores by 25%.
RAG systems learn from every interaction, refining retrieval accuracy over time. This adaptive capability bridges the gap between automation and empathy, making RAG a cornerstone for scalable, high-quality support. The future lies in leveraging this adaptability to anticipate—not just react to—customer needs.
Improving Knowledge Management
RAG APIs transform knowledge management by enabling contextual retrieval across fragmented data silos. Instead of relying on keyword-based searches, these systems use dense vector embeddings to understand semantic relationships, delivering precise, actionable insights. This approach is particularly effective in enterprises where employees waste hours sifting through outdated or irrelevant documents.
Consider a multinational consulting firm. By deploying RAG, they integrated internal reports, client data, and industry research into a unified knowledge base. Employees could query the system in natural language—e.g., “What are the latest trends in renewable energy?”—and receive concise, up-to-date summaries. This reduced research time by 35% and improved proposal quality.
Metadata tagging. By enriching documents with metadata during ingestion, RAG systems enhance retrieval accuracy. Organizations must prioritize robust data curation processes. Future advancements could see RAG APIs integrating with real-time analytics tools, turning static knowledge bases into dynamic decision-making engines.
Content Generation and Personalization
RAG in content generation dynamically adapts outputs based on user-specific contexts, retrieving real-time data tailored to individual preferences for hyper-personalized content. For instance, a marketing team can use RAG to generate email campaigns that incorporate a customer’s purchase history, browsing behavior, and even seasonal trends, boosting engagement rates by up to 40%.
Contextual layering drives success by combining retrieval from multiple sources—like CRM systems and external market data—ensuring outputs are both relevant and timely. This approach bridges the gap between personalization and accuracy, a challenge traditional AI models often fail to address.
To maximize impact, organizations should invest in feedback loops. These systems refine personalization by learning from user interactions, creating a virtuous cycle of improvement. Looking ahead, integrating RAG with predictive analytics could redefine how businesses anticipate and meet customer needs.
Comparative Analysis
When comparing RAG APIs to traditional retrieval systems, the distinction lies in their ability to synthesize information rather than merely retrieve it. Traditional systems act like search engines—efficient but limited to presenting raw data. RAG, however, functions more like a skilled analyst, weaving retrieved data into coherent, actionable insights. For instance, in e-commerce, RAG doesn’t just list products; it generates personalized recommendations by analyzing user behavior and inventory trends.
RAG doesn’t sacrifice speed for depth. Advancements like vector embeddings and adaptive chunking have proven it can achieve both efficiently. A 2024 case study in financial services showed RAG reducing query response times by 40% while improving accuracy in risk assessments.
RAG’s strength lies in its feedback loops, which refine both retrieval and generation over time. This iterative learning mirrors human expertise, making RAG indispensable in dynamic fields like healthcare and legal research.
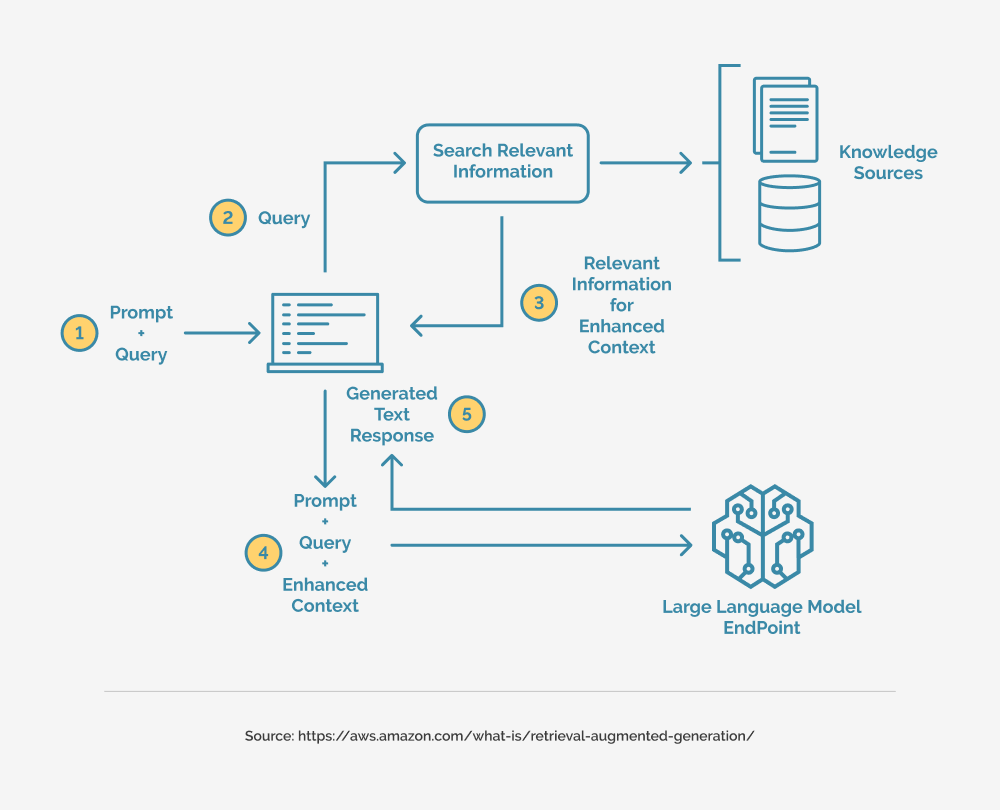
RAG API vs Traditional APIs
Traditional APIs excel at static data retrieval, offering predictable outputs from predefined datasets. But in dynamic environments—think fraud detection or real-time customer support—this rigidity becomes a bottleneck. RAG APIs, by contrast, thrive on contextual adaptability, blending retrieval with generative capabilities to deliver nuanced, situation-specific responses. For example, a RAG-powered legal assistant doesn’t just retrieve case law; it synthesizes rulings into actionable legal strategies.
Traditional APIs often rely on cached or outdated data, while RAG APIs integrate live sources, ensuring relevance. A 2025 study in healthcare found that RAG systems reduced diagnostic errors by 30% by incorporating the latest medical research into their outputs.
Unlike traditional APIs, RAG APIs improve over time, refining their outputs based on user feedback. This positions them as indispensable tools in industries where precision and adaptability are non-negotiable.
Advantages over Competing Solutions
One standout advantage of RAG APIs is their ability to mitigate hallucinations—a persistent issue in generative AI. Unlike competing solutions that rely solely on pre-trained models, RAG APIs ground their outputs in real-time, verified data. For instance, in financial services, a RAG-powered assistant can pull live market data to generate accurate investment insights, avoiding speculative or outdated recommendations.
Traditional models often require extensive fine-tuning to adapt to new domains, but RAG APIs dynamically integrate external knowledge bases. This makes them ideal for industries like e-commerce, where product catalogs and user preferences change frequently.
RAG APIs excel in multi-modal integration, seamlessly combining text, images, and structured data. This capability is transforming fields like healthcare, where patient records, imaging data, and clinical guidelines must converge for precise diagnostics. Moving forward, this adaptability positions RAG APIs as a cornerstone for next-gen AI solutions.
Limitations and Considerations
If the retrieval mechanism pulls from biased, outdated, or incomplete sources, the generated outputs will reflect these flaws. For example, in legal applications, relying on unverified case law databases can lead to inaccurate or even harmful advice, undermining user trust.
Another challenge is latency in real-time retrieval. While RAG systems excel at dynamic data integration, the retrieval process can introduce delays, especially when querying large or distributed datasets. This is particularly problematic in high-stakes environments like healthcare, where response time directly impacts decision-making.
Combining retrieval and generative components requires seamless orchestration, which can strain resources during deployment. To address this, organizations should adopt modular architectures and prioritize data validation pipelines. By doing so, they can mitigate risks and unlock the full potential of RAG systems in mission-critical applications.
Future Trends and Developments
The future of RAG APIs is poised to revolve around contextual intelligence. Emerging systems will not only retrieve relevant data but also interpret the broader context of user queries. For instance, in financial forecasting, RAG could analyze market sentiment alongside historical data, offering nuanced predictions that adapt to real-time events.
The integration of multimodal capabilities allows RAG APIs to process text, images, and even audio simultaneously, potentially revolutionizing industries like e-commerce. Imagine a system that combines customer reviews, product images, and video tutorials to generate personalized shopping recommendations.
Ethical AI frameworks will shape RAG’s evolution. As reliance on external data grows, ensuring transparency and fairness in retrieval processes becomes critical. Companies like OpenAI are already exploring ways to audit and mitigate biases in generative outputs, setting a precedent for responsible innovation. These advancements promise to redefine how we interact with and trust AI systems.
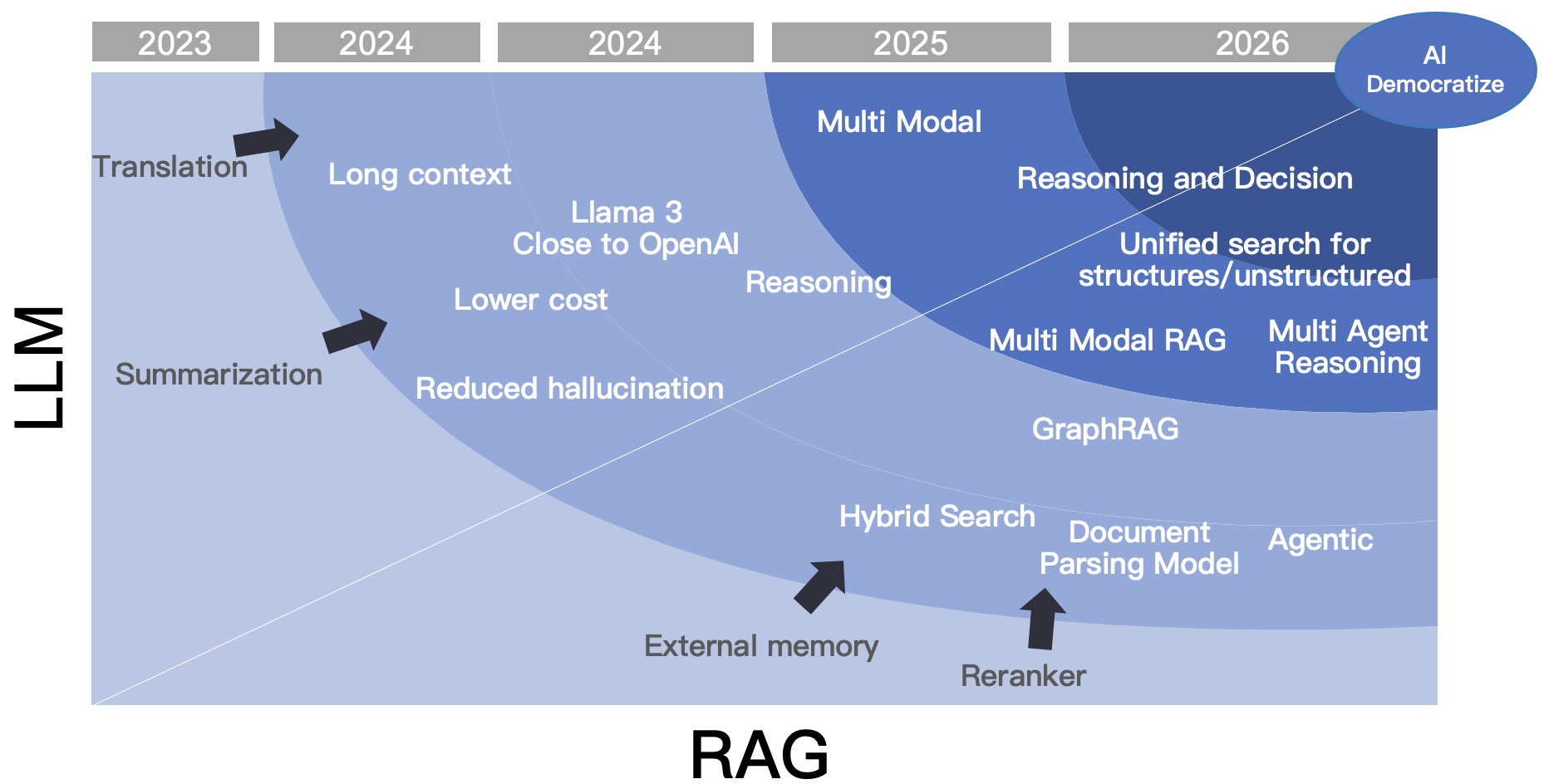
Emerging Technologies in Retrieval-Augmented Generation
One of the most exciting frontiers in RAG is the integration of brain-computer interfaces (BCIs). By leveraging neural signals, BCIs could enable RAG systems to interpret user intent at an unprecedented level of granularity. For example, assistive technologies for individuals with disabilities could combine BCI inputs with RAG to generate context-aware responses tailored to non-verbal cues, transforming accessibility.
RAG-powered AR systems could overlay real-time, contextually relevant information—like historical facts during a museum tour or live stats during a sports event. This fusion of retrieval and immersive tech creates a seamless blend of physical and digital experiences.
These advancements hinge on data governance. Without robust frameworks to manage privacy and bias, the potential of these technologies could be undermined. Developers must prioritize ethical design to ensure these innovations serve diverse user needs responsibly.
Upcoming Features in RAG API
This approach dynamically adjusts retrieval parameters based on user behavior and query history. For instance, in e-commerce, a RAG API could refine product recommendations in real time by analyzing browsing patterns, leading to hyper-personalized shopping experiences.
Multi-modal data integration enables RAG APIs to combine text, images, and even audio inputs, delivering richer, more nuanced outputs. Imagine a healthcare application where a doctor uploads an X-ray image alongside patient notes, and the RAG API synthesizes a detailed diagnostic report by retrieving relevant medical literature.
These advancements require fine-tuned vector embeddings to ensure precision across diverse data types. Developers must also address challenges like latency and computational overhead. By prioritizing these innovations, RAG APIs can redefine how industries interact with complex, real-time data ecosystems.
The Impact on AI and Machine Learning Fields
RAG APIs streamline feature engineering by automating the retrieval of high-value data correlations from historical datasets, reducing the manual effort traditionally required. For example, a machine learning team could use RAG to identify key predictors for customer churn, cutting down weeks of exploratory analysis into hours.
RAG also enhances model training efficiency by ensuring only relevant, high-quality data is retrieved. This minimizes noise in training datasets, leading to faster convergence and improved model accuracy. In real-world applications, such as fraud detection, this precision allows models to adapt quickly to emerging patterns without retraining on outdated data.
The integration of RAG into ML workflows demands robust data governance frameworks. Without these, biases in retrieved data could propagate into models. Moving forward, RAG’s role in adaptive learning systems could redefine how AI evolves in dynamic environments.
FAQ
1. What are the core components of a RAG API and how do they interact?
A RAG API consists of three key components: Retrieval Mechanism, Augmentation Engine, and Generation Engine. The Retrieval Mechanism fetches relevant data from external sources, using techniques like vector embeddings for precise alignment with the user’s query. The Augmentation Engine integrates this data into the input prompt for the generative model, ensuring contextually relevant content. The Generation Engine synthesizes the augmented input into coherent, factually accurate responses, blending pre-trained knowledge with retrieved data. These components interact dynamically, ensuring the most relevant data is prioritized, delivering real-time, contextually enriched responses.
2. How does a RAG API ensure the accuracy and relevance of its outputs?
A RAG API ensures output accuracy and relevance through advanced retrieval techniques, contextual augmentation, and iterative feedback.
- Advanced Retrieval: It uses dense vector embeddings and semantic search to fetch highly relevant data, ensuring precision and contextual alignment.
- Contextual Augmentation: Retrieved data is integrated into the input for the generative model, grounding outputs in factual, up-to-date information and minimizing hallucinations.
- Iterative Feedback: The RAG API refines its retrieval and generation based on user feedback, ensuring continuous improvement and better meeting user needs.
With metadata tagging and domain-specific knowledge bases, the system further enhances retrieval precision, delivering outputs that are both accurate and relevant.
3. What are the primary use cases for RAG APIs across different industries?
RAG APIs transform industries by combining real-time data retrieval with generative capabilities to tackle complex challenges.
- Healthcare: RAG APIs help medical professionals by synthesizing clinical evidence, retrieving the latest research, and providing personalized treatment recommendations for better patient outcomes.
- Legal Services: In legal domains, RAG APIs streamline case preparation by retrieving precedents, regulations, and legal texts, generating summaries, and flagging updates, reducing research time and enhancing accuracy.
- E-commerce: RAG APIs improve customer experiences by offering personalized product recommendations, real-time inventory updates, and context-aware responses, reducing cart abandonment and increasing satisfaction.
- Education: RAG-powered tutoring systems create personalized study plans and provide real-time feedback, adapting to individual student needs.
- Telecommunications: RAG APIs optimize network performance, troubleshooting issues and offering predictive maintenance to reduce downtime.
- Finance: RAG APIs aid financial institutions with fraud detection, market analysis, and investment insights, improving decision-making and risk management.
4. What challenges might arise when implementing a RAG API, and how can they be mitigated?
Implementing a RAG API can present challenges, but strategic planning and system design can mitigate these issues.
- Integration Complexity: Combining retrieval systems with generative models, especially when handling multiple data sources, can be tricky. Using modular architectures and preprocessing pipelines ensures consistent data embeddings and model standardization.
- Scalability Issues: As data grows, efficient retrieval and generation can become difficult. Distributed architectures, index sharding, and caching mechanisms can optimize performance and reduce latency.
- Data Quality and Bias: Poor or biased data leads to inaccurate results. Regular audits, fine-tuning with curated datasets, and bias detection algorithms ensure fairness and accuracy.
- Latency Concerns: Real-time applications may experience delays. Query optimization, parallel processing, and hardware acceleration help reduce response times.
- Security and Privacy Risks: Safeguarding sensitive data requires encryption, secure cloud infrastructures, and regular compliance checks.
By addressing these challenges, organizations can optimize the RAG API’s benefits.
5. How does a RAG API differ from traditional APIs in terms of functionality and benefits?
A RAG API differs from traditional APIs in functionality and benefits by integrating real-time data retrieval with generative AI, offering a more dynamic, context-aware approach.
Functionality:
- Traditional APIs: Focus on static data retrieval, providing predefined responses or access to datasets, relying on keyword-based searches.
- RAG APIs: Combine retrieval mechanisms with generative models to dynamically fetch and contextualize data, generating coherent, tailored responses for complex queries.
Benefits:
- Contextual Relevance: RAG APIs deliver up-to-date, relevant information grounded in real-time data, while traditional APIs may offer outdated results.
- Adaptability: RAG APIs adapt to evolving datasets, ensuring continuous accuracy, unlike traditional APIs that need manual updates.
- Enhanced User Experience: RAG APIs synthesize data into actionable insights, improving user satisfaction and reducing the need for multiple sources.
RAG APIs bridge static retrieval and dynamic generation, redefining API functionality.
Conclusion
Think of a RAG API as the bridge between a static library and a live newsroom. Traditional APIs are like bookshelves—organized but fixed. RAG APIs, on the other hand, are dynamic reporters, pulling in breaking news and weaving it into coherent narratives. This distinction is not just theoretical; it’s transformative.
Take customer support as an example. A traditional API might retrieve a product manual, but a RAG API can fetch the latest firmware update and explain how it solves a user’s issue—all in real time. In a case study by Algo Communications, integrating RAG boosted first-contact resolution rates by 35%, proving its practical impact.
Some believe RAG APIs are prohibitively complex. In reality, modular architectures and tools like vector embeddings simplify implementation. Experts agree: the key is pairing high-quality data with adaptive retrieval strategies.
In short, RAG APIs don’t just answer questions—they evolve with them.