
How To Use RAG for Code Generation
Learn how to use Retrieval-Augmented Generation (RAG) for code generation by integrating structured knowledge retrieval with AI models. Improve code accuracy, automate development tasks, enhance debugging, and generate context-aware code snippets efficiently.


The very tools designed to make coding easier—frameworks, libraries, and templates—are now the bottleneck. Developers spend hours sifting through documentation, piecing together boilerplate code, and debugging repetitive patterns. It’s ironic, isn’t it? The tools meant to save time often end up consuming it.
Retrieval-Augmented Generation (RAG) flips this script entirely. By combining the precision of information retrieval with the creativity of generative AI, RAG doesn’t just automate code generation—it tailors it to your project’s unique context. This isn’t about generic snippets; it’s about creating code that feels like it was written by someone who knows your system inside out.
But here’s the real question: can RAG truly replace the manual grind of coding without sacrificing quality or control? And if so, what does that mean for the future of software development? Let’s explore.
What is Retrieval-Augmented Generation (RAG)?
RAG is a powerful AI approach that goes beyond pre-trained knowledge by actively retrieving real-time data from external sources. It’s like combining a researcher and a writer—one gathers facts, the other crafts responses—ensuring accuracy and context.
RAG shines where static models struggle, like legal tech (pulling case precedents for arguments) or e-commerce (fetching product specs for recommendations). However, its effectiveness depends on the quality of retrieval, making optimization crucial. When done right, RAG bridges the gap between static AI and dynamic, domain-specific intelligence.
The Evolution of Code Generation
Code generation has come a long way, but the real breakthrough lies in how RAG integrates contextual awareness. Unlike traditional models that spit out generic snippets, RAG tailors its output by retrieving project-specific data—like internal libraries or team coding standards. This isn’t just automation; it’s collaboration between AI and developer intent.
Take debugging, for instance. Instead of manually sifting through error logs, RAG pulls relevant fixes from your issue tracker or even Stack Overflow. It doesn’t just save time—it reduces cognitive load, letting developers focus on solving problems rather than finding them.
RAG also democratizes coding. By turning natural language prompts into functional code, it empowers non-developers to prototype ideas. The result? Faster innovation cycles and fewer bottlenecks. Moving forward, the challenge will be balancing this accessibility with maintaining code quality and security—a frontier worth exploring.
Benefits of Using RAG in Code Generation
RAG helps reduce technical debt by ensuring code consistency across projects. By retrieving reusable components and design patterns, it minimizes redundant or poorly structured code, making systems more scalable and maintainable.
In large teams, RAG aligns outputs with internal coding standards by referencing style guides or past commits, reducing code review efforts and improving collaboration—like having a senior developer available 24/7.
Beyond developers, RAG also empowers cross-functional teams. A product manager, for instance, can generate prototype code that follows best practices, speeding up development without compromising quality. To maximize its benefits, organizations need well-curated knowledge bases.
Understanding the Core Concepts
Retrieval-Augmented Generation (RAG) marries two forces: retrieval and generation. Imagine a chef who not only remembers recipes but also picks the freshest ingredients to create a dish just for you. This blend ensures outputs are relevant and rich in context. However, RAG’s success hinges on a strong knowledge base—a poor one can lead to misguided results, much like using expired ingredients. When paired with trusted sources like GitHub repositories or internal docs, RAG becomes a powerful tool for producing clean, functional code.
The Mechanics of Retrieval Systems
The retriever in RAG is like a skilled librarian who finds the exact page you need rather than just any book. Using techniques like vector embeddings, it maps queries and documents into a shared space for precise matching.
In environments with domain-specific data, such as proprietary APIs, this method can save significant debugging time. Regular updates and a feedback loop are key to keeping the retriever sharp, ensuring it anticipates user needs accurately.
Language Models in Code Generation
Language models in code generation need solid context to excel. By fine-tuning these models on domain-specific data, they can grasp the nuances of internal coding standards or niche frameworks.
For example, a fintech firm fine-tuned its model on proprietary APIs, leading to code suggestions that met internal security protocols while reducing manual reviews. Enhancing outputs further, detailed prompts act like a well-drawn map, guiding the model with clarity.
Integrating Retrieval with Generation
A retrieval-first workflow grounds the generative process in real-time, domain-specific data, reducing hallucinations and aligning outputs with current, relevant info.
Take a healthcare chatbot that fetches up-to-date clinical guidelines before offering advice—this builds user trust and ensures accuracy. The success of this hybrid approach depends on well-tuned vector embeddings and ongoing fine-tuning, creating a system that evolves with changing data while maintaining top performance.
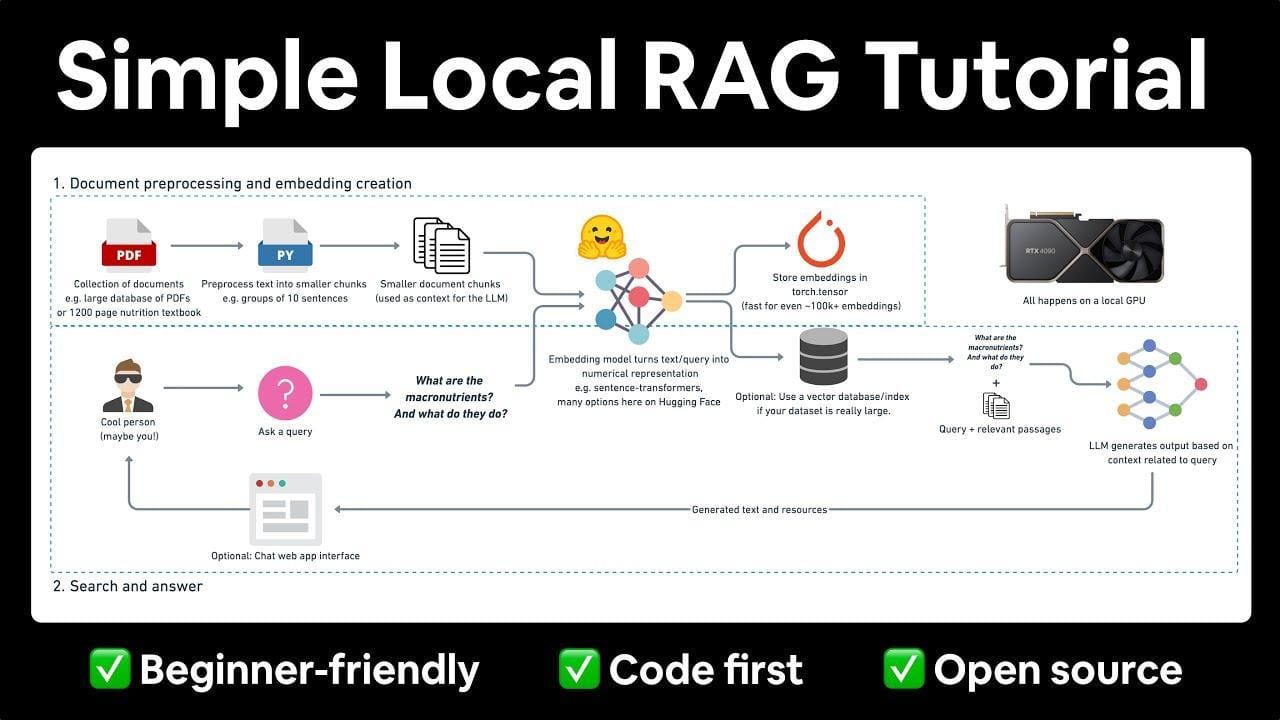
Setting Up a RAG System for Code Generation
Think of setting up a RAG system like building a custom toolbox—it’s all about having the right tools for the job. Start with a well-curated knowledge base. This isn’t just about dumping documentation into a database; it’s about structuring it for fast, accurate retrieval. For example, a fintech company might index API docs, compliance rules, and past code snippets to ensure the system generates secure, functional code.
Next, focus on the retrieval mechanism. Tools like FAISS or Elasticsearch can help, but the real game-changer is embedding quality. Poor embeddings? Your system retrieves junk. Fine-tune embeddings using domain-specific data to ensure precision.
Here’s the twist: don’t overlook feedback loops. Developers can flag irrelevant suggestions, which the system uses to refine future outputs. It’s like teaching a junior developer—iterative and rewarding.
Finally, integrate lightweight prompt engineering. Clear, structured prompts guide the generative model, ensuring outputs align with your coding standards.
1. Required Tools and Libraries
When it comes to tools, vector databases like FAISS or Pinecone are non-negotiable. Why? They make retrieval lightning-fast by organizing your data into embeddings that the system can search efficiently. But the quality of these embeddings depends heavily on your choice of embedding models. OpenAI’s Ada or Cohere’s embeddings are great starting points, but fine-tuning them on your domain-specific data can take your RAG system from “meh” to “wow.”
For libraries, LangChain is a standout. It simplifies the integration of retrieval and generation workflows, letting you focus on building rather than debugging. Pair it with Hugging Face Transformers to leverage pre-trained models for tasks like code generation or documentation.
Pro tip: Don’t ignore monitoring tools. Libraries like Prometheus or Grafana can track retrieval accuracy and latency, helping you spot bottlenecks early. Think of them as your system’s health dashboard—essential for scaling effectively.
2. Preparing the Knowledge Base
Your knowledge base isn’t just a repository—it’s the backbone of your RAG system. Start by curating high-quality, domain-specific data. This means pulling from internal documentation, codebases, and even issue trackers. But don’t stop there. Include external sources like GitHub repositories or Stack Overflow threads to add depth and diversity.
Now, let’s talk structure. Use embedding models to convert your data into searchable vectors. But here’s a twist: prioritize metadata tagging. For example, tagging code snippets with programming languages, frameworks, or even project phases can drastically improve retrieval accuracy. Think of it as giving your system a map instead of a maze.
One overlooked factor? Data freshness. Outdated knowledge leads to irrelevant results. Automate updates with tools like DVC (Data Version Control) to keep your base current. Trust me, a well-maintained knowledge base doesn’t just support your RAG system—it supercharges it.
3. Configuring the Retrieval Component
Your retrieval component isn’t just about speed—it’s about precision. Start by using vector embeddings tailored to your domain. For example, if you’re working with Python code, opt for embeddings fine-tuned on programming languages. This ensures your system retrieves relevant snippets, not random noise.
But here’s where it gets interesting: multi-vector indexing. Instead of relying on a single embedding, use multiple embeddings for different data types—like code, documentation, and error logs. This layered approach boosts accuracy by matching queries to the right context. Think of it as having a specialist for every task.
Now, let’s address a hidden factor: query optimization. Use techniques like query expansion to include synonyms or related terms. For instance, a search for “bug” could also retrieve results tagged with “error” or “issue.” The result? A retrieval system that feels intuitive and delivers spot-on results every time.
4. Connecting Retrieval to the Generation Model
The magic happens when retrieval and generation work in sync. The key is embedding alignment—ensuring the vector space used for retrieval matches the one the generation model understands. Without this, your generative model might misinterpret retrieved data, leading to irrelevant or incoherent outputs.
Now, let’s talk context packaging. Instead of dumping raw retrieved data into the model, structure it. For example, prepend retrieved code snippets with metadata like file paths or function names. This gives the model a richer context to generate more accurate and actionable outputs.
Here’s a lesser-known trick: dynamic weighting. Not all retrieved data is equally relevant. Use scoring mechanisms to prioritize high-confidence results. For instance, in debugging, prioritize logs with recent timestamps. This approach not only improves output quality but also reduces noise, making your RAG system feel smarter and more intuitive.
Implementing Code Generation with RAG
Using RAG for code generation is like having a supercharged assistant that knows your codebase inside and out. Instead of starting from scratch, it pulls in relevant code snippets from repositories or internal knowledge bases, grounding its outputs in real-world examples. For instance, if you're building an API, RAG can fetch boilerplate code for authentication, adjust it to your framework, and even suggest parameter tweaks—cutting down on bugs and aligning with best practices. It doesn’t replace your creativity but handles the repetitive work, letting you focus on unique challenges.

Creating Effective Prompts
Crafting detailed prompts is key. A vague request like “generate a login function” may produce generic code, but adding specifics—framework details, authentication methods, or edge cases—turns it into a precise blueprint. Think of it as giving clear instructions: the more detail you provide (like “write a Python function using json.loads to parse a JSON string and handle invalid inputs with exceptions”), the better the output. Iterative refinement also helps: start broad, review, and tweak until the code fits perfectly.
Managing Context and Dependencies
RAG excels when you structure retrieved data to reflect your project’s flow. When generating a function that interacts with a database, include details like schema, connection methods, and constraints to minimize guesswork. A handy trick is dependency mapping—retrieving related modules or libraries beforehand ensures seamless integration. Don’t forget to specify library or framework versions in your prompts to avoid subtle, hard-to-debug issues.
Generating Modular Code
Break down code generation into smaller, self-contained units rather than one large module. For example, instead of asking for a complete authentication module, prompt RAG to generate specific components like token validation or password hashing. Using incremental prompts—starting with high-level requirements and then zooming in on details—helps maintain logical consistency and makes debugging easier.
Testing and Validation
Integrate testing right into the generated code. Prompt RAG to produce both a function and its corresponding unit tests to catch errors early. Pair your RAG outputs with static analyzers or linters (like Pylint for Python) to ensure the code meets your standards and handles edge cases. Testing across multiple library versions further ensures compatibility in fast-changing environments. In short, treat validation as a continuous loop: test, refine, and iterate for robust, production-ready code.
Advanced Usage and Optimization
Imagine RAG as a smart GPS that recalculates your route based on traffic. With dynamic retrieval prioritization, you can assign weights to data—favoring recent commits or highly-rated snippets—to ensure your generated code stays current. For example, pulling from active GitHub repositories minimizes outdated solutions. Plus, by integrating domain-specific elements (like medical ontologies for healthcare apps), RAG can deliver code that not only works but also complies with industry regulations.
1. Customizing the Retrieval Strategy
Not all retrieval strategies are equal. For projects with complex, layered dependencies—like microservices—recursive retrieval digs deep, pulling every related component (from endpoints to authentication methods).
In dynamic settings, such as debugging a live e-commerce platform during a flash sale, adaptive retrieval prioritizes recent logs and commits, ensuring fixes are based on the latest context. Fine-tuning your queries with domain-specific keywords further sharpens the system’s ability to fetch the right data.
2. Fine-Tuning Models for Specific Languages
Fine-tuning isn’t just about more data—it’s about understanding language nuances. Whether it’s Python’s flexible syntax or Java’s strict type system, training with language-specific idioms (like Python’s list comprehensions or Java’s try-with-resources) ensures that the generated code feels natural.
Domain-adaptive pretraining on real-world projects, such as Django for Python or Spring Boot for Java, reduces syntax errors and makes suggestions more contextually relevant. Don’t forget to analyze and adjust for common error patterns, like off-by-one mistakes, to create a system that writes code you’d actually use.
3. Scaling RAG Systems for Large Projects
As projects grow, so do data sources. Federated retrieval—querying multiple databases in parallel—helps avoid bottlenecks and speeds up response times. Pre-ranking data sources using metadata or historical query patterns can significantly cut down on unnecessary retrievals, as demonstrated by a DevOps team that reduced latency by 40%.
Leveraging auto-scaling cloud services also ensures that your system adapts smoothly to spikes in demand, proving that smart resource management is key to scaling successfully.
4. Integrating Feedback Loops for Improvement
Real-time feedback is a game-changer. Embedding user input (like thumbs-up/down ratings) directly into the retrieval and generation cycle lets the system adjust dynamically, favoring more relevant data over time. Automatic feedback mechanisms—such as classifiers that flag low-confidence outputs—can trigger corrective actions without human intervention.
Moreover, contextual feedback (tied to specific use cases like debugging logs versus API documentation) ensures that the system evolves in meaningful ways. Ultimately, these feedback loops help build a RAG system that learns smarter, not just harder.
Case Studies and Real-World Applications
Let’s talk about how RAG is making waves in the real world. Take GitHub Copilot, for example. By integrating RAG, it retrieves context-specific code snippets from vast repositories, helping developers write efficient code faster. One team reported a 40% reduction in development time for repetitive tasks like boilerplate generation. That’s not just faster—it’s smarter.
Now, contrast that with healthcare. A hospital network used RAG to enhance its knowledge base, retrieving clinical guidelines tailored to specific cases. The result? Doctors spent 30% less time searching for information, allowing them to focus on patient care. It’s like having a medical librarian on speed dial.
RAG isn’t just about speed—it’s about precision. In e-commerce, a platform improved product search by combining retrieval with generative descriptions, boosting conversion rates by 15%. Whether it’s debugging code or saving lives, RAG proves that context is king.
Automating Boilerplate Code Generation
Boilerplate code is the broccoli of software development—necessary but tedious. RAG flips the script by pulling reusable patterns from internal repositories and external libraries, then tailoring them to your project’s context. For instance, a fintech startup used RAG to auto-generate API integration templates, cutting onboarding time for new developers by 50%. That’s not just efficiency; it’s onboarding with a turbo boost.
Here’s why it works: RAG doesn’t just retrieve code—it understands why it’s relevant. By analyzing metadata like function usage and dependencies, it ensures the generated code aligns with your architecture. Think of it as a sous-chef who preps exactly what you need, no more, no less.
Enhancing Developer Productivity
Let’s talk about meetings—the productivity killer. RAG can eliminate the need for endless clarification sessions by acting as a real-time knowledge hub. For example, a SaaS company integrated RAG into their IDE, enabling developers to instantly retrieve project-specific guidelines, past decisions, and even code review notes. The result? Fewer interruptions, more deep work.
Here’s the magic: RAG thrives on context. By combining retrieval with generative capabilities, it delivers not just answers but actionable insights tailored to the task at hand. This is especially powerful during debugging, where RAG can surface relevant error logs and past fixes, slashing resolution times.
RAG in Collaborative Coding Environments
Team coding can suffer from miscommunication, but RAG helps keep everyone on the same page. For example, a fintech startup used RAG to centralize code reviews, allowing developers to instantly access annotated feedback and historical decisions. This streamlined process reduced redundant discussions and reinforced coding standards.
RAG works best with a structured knowledge base—tagged code snippets with metadata like author notes and dependencies create a shared context for all. This is especially beneficial for remote teams, where asynchronous collaboration can lead to gaps in understanding.
For even better results, integrate RAG with version control systems. This way, each pull request comes with context-aware suggestions, making reviews faster and more insightful. The end result is a collaborative coding environment that feels seamless rather than chaotic.
Challenges and Considerations
Let’s talk about the elephant in the room: data quality. RAG systems are only as good as the knowledge base they pull from. Imagine feeding outdated or poorly tagged code snippets into the system—it’s like asking a GPS to navigate with a 10-year-old map. A real-world example? A retail company’s RAG tool suggested deprecated APIs, leading to hours of rework. The fix? Regularly auditing and updating the knowledge base.
Another curveball? Balancing retrieval precision with speed. Developers want answers fast, but overly broad retrieval can flood them with irrelevant results. Think of it like searching for a needle in a haystack—except the haystack keeps growing. Techniques like multi-vector indexing can help, but they require careful tuning.
Finally, privacy concerns can’t be ignored. Using proprietary or sensitive data in RAG systems demands airtight compliance with regulations like GDPR. Without it, you’re risking more than just bad code—you’re risking trust.
Ensuring Code Quality and Reliability
Context is king when it comes to code quality. RAG systems thrive on well-structured, domain-specific knowledge bases, but here’s a twist—context layering can make or break reliability. For example, a fintech company used RAG to generate compliance-critical code. By embedding regulatory guidelines directly into the retrieval layer, they avoided costly errors. Without this, the system might’ve generated code that passed tests but failed audits.
Another overlooked factor? Dependency mapping. RAG can retrieve snippets that work in isolation but break when integrated. Think of it like assembling IKEA furniture without checking if all the screws fit. A better approach? Use dependency-aware prompts that account for versioning and compatibility.
Finally, don’t underestimate automated testing integration. Embedding unit tests into generated code isn’t just a nice-to-have—it’s essential. It’s like having a safety net that catches issues before they spiral into production nightmares.
Addressing Security Concerns
Let’s talk about data leakage—a sneaky risk in RAG systems. when RAG retrieves sensitive data, it’s not just about encryption. The real game-changer is query anonymization. By stripping identifiable metadata from queries, you prevent exposing proprietary information during retrieval. For instance, a healthcare provider used this approach to safeguard patient data while still leveraging RAG for real-time diagnostics.
Another underappreciated tactic? Access throttling. Think of it as a speed bump for malicious actors. By limiting query rates and implementing role-based access controls, you reduce the risk of unauthorized data scraping. This is especially critical in multi-tenant environments where one breach could cascade.
Finally, don’t sleep on red teaming. Simulating attacks on your RAG pipeline uncovers vulnerabilities you didn’t know existed. It’s like stress-testing a bridge before letting traffic flow. The takeaway? Security isn’t static—it’s a living, breathing process.
Ethical Implications of Automated Code Generation
Let’s zero in on algorithmic bias—a silent disruptor in automated code generation. bias often sneaks in through training data. If your RAG system pulls from repositories with skewed patterns (e.g., underrepresentation of certain programming paradigms), it can perpetuate inequities. For example, a fintech company found their model favoring legacy systems over modern, inclusive frameworks, stalling innovation.
One effective fix? Diverse data curation. By sourcing from a wide range of repositories and auditing for inclusivity, you can reduce bias at the root. Another game-changer is bias-aware prompts. These guide the system to prioritize fairness, like ensuring gender-neutral variable names or avoiding culturally loaded terms.
But here’s the twist: bias isn’t just technical—it’s cultural. Engaging diverse stakeholders during development can surface blind spots you’d never catch alone. The result? Systems that don’t just generate code but foster equity in tech.
FAQ
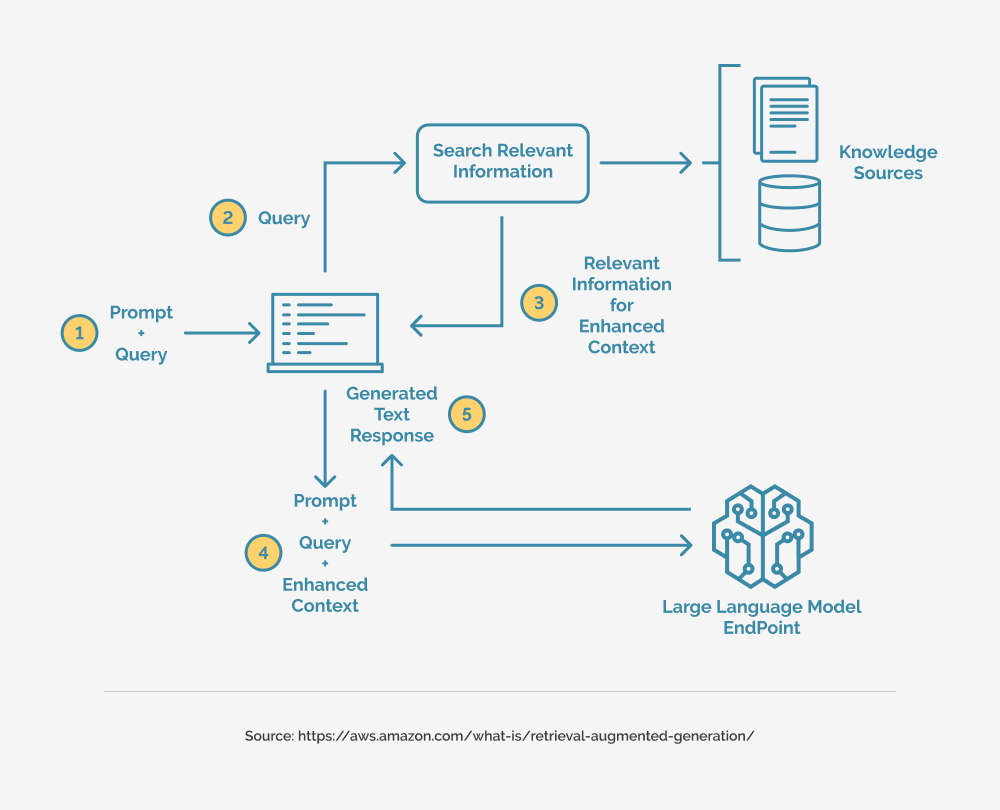
1. What is Retrieval-Augmented Generation (RAG) and how does it enhance code generation?
Retrieval-Augmented Generation (RAG) is a cutting-edge AI technique that combines the strengths of retrieval-based methods and generative models to produce contextually accurate and information-rich outputs. In the context of code generation, RAG enhances the process by retrieving relevant, real-time data from external knowledge bases, such as code repositories, documentation, or issue trackers, and integrating this information into the generated code.
This approach ensures that the outputs are not only aligned with the latest standards and practices but also tailored to specific project requirements. By reducing reliance on static training data, RAG minimizes errors, accelerates development workflows, and empowers developers to create robust, high-quality code with greater efficiency.
2. How can RAG be integrated into existing software development workflows?
RAG can be seamlessly integrated into existing software development workflows by embedding it within commonly used tools and processes. Start by incorporating RAG-enabled plugins into Integrated Development Environments (IDEs) to provide context-aware code suggestions and completions. Enhance your debugging process by using RAG to retrieve relevant error resolutions from internal issue trackers or external forums.
For documentation, RAG can automate updates by analyzing code changes and generating synchronized documentation. Additionally, integrating RAG with version control systems allows for contextually enriched code reviews, ensuring alignment with project standards. By tailoring RAG to your team’s specific needs and maintaining an up-to-date knowledge base, it becomes a powerful assistant that complements and enhances your existing development practices.
3. What are the best practices for preparing a knowledge base for RAG in code generation?
Preparing a knowledge base for RAG in code generation requires a structured and meticulous approach to ensure relevance and accuracy. Begin by curating high-quality, domain-specific data, including code snippets, documentation, and best practices, while eliminating outdated or redundant information.
Organize the data with metadata tagging to enhance retrieval precision and ensure that the knowledge base is easily searchable. Automate regular updates to keep the information current and aligned with evolving project requirements. Incorporate feedback loops from developers to refine the knowledge base continuously, addressing gaps or inaccuracies.
Finally, prioritize security and compliance by anonymizing sensitive data and adhering to regulatory standards, ensuring the knowledge base is both robust and trustworthy.
4. How does RAG ensure the accuracy and reliability of generated code?
RAG ensures the accuracy and reliability of generated code by grounding its outputs in real-time, contextually relevant data retrieved from trusted external sources. By leveraging a well-maintained knowledge base, RAG minimizes the risk of hallucinations and outdated information, producing code that aligns with current standards and practices.
The retrieval component dynamically fetches precise snippets or documentation tailored to the task, while the generative model integrates this data to create coherent and functional outputs. Additionally, incorporating automated testing and validation mechanisms during the generation process further enhances reliability, ensuring that the generated code meets quality benchmarks and integrates seamlessly into existing systems.
5. What tools and frameworks are recommended for implementing RAG in code generation projects?
Implementing RAG in code generation projects benefits greatly from leveraging specialized tools and frameworks. Vector databases like FAISS and Pinecone are essential for efficient data retrieval, enabling quick access to relevant information.
Libraries such as LangChain and Hugging Face Transformers provide robust support for integrating retrieval and generation components, streamlining the development process.
LlamaIndex is another valuable tool, aiding in data processing and model training to ensure seamless integration of machine learning components. For monitoring and maintaining system health, tools like Prometheus and Grafana are highly recommended. By combining these resources, developers can build scalable, efficient, and reliable RAG systems tailored to their specific project needs.
Conclusion
RAG isn’t just a tool—it’s a bridge between static knowledge and dynamic problem-solving in code generation. Think of it as a well-trained sous-chef in a bustling kitchen, fetching the exact ingredients you need, exactly when you need them. By integrating RAG into workflows, developers can focus on creativity while the system handles the grunt work of retrieval and synthesis.
Take GitHub Copilot, for example. It’s not just speeding up coding; it’s reducing bugs by referencing real-world examples from vast repositories. Similarly, in a healthcare project, RAG cut development time by 30% by pulling domain-specific code snippets directly into prototypes. These aren’t just efficiency gains—they’re paradigm shifts.
But RAG thrives on quality inputs. A poorly curated knowledge base is like a cluttered pantry—chaos in, chaos out. Invest in your data, and RAG will return the favor tenfold.